Scanna med OCR

|
I det här läget kan du utföra OCR (optisk teckenigenkänning) för att extrahera data som kan kännas igen som text från den scannade bilden, och skapa en sökbar fil med något av formaten PDF/XPS/OOXML (pptx/docx). Du kan även ange <Kompakt> om du väljer PDF eller XPS som filformat.
För information om vilka tillvalsprodukter och filformat som krävs för att använda den här funktionen, se Systemalternativ.
|
Scanna med OCR
1
Placera originalet. Placera original
2
Tryck på <Scanna och skicka>. Skärmbilden <Huvudmeny>
3
Ange mottagare på skärmbilden med grundläggande scanningsfunktioner. Skärmbilden med grundläggande scanningsfunktioner
4
Ange lämpliga scanningsinställningar. Grundläggande funktioner för scanning av original
5
Välj ett filformat.
Om du vill dela upp flera bilder och skicka dem som separata filer med en sida i varje fil, trycker du på <Dela upp i sidor>  ange antalet sidor som ska delas upp genom att trycka på <OK>. Om du vill scanna bilderna som en gemensam fil, tryck på <Dela upp i sidor> <Avbryt inställning>.
ange antalet sidor som ska delas upp genom att trycka på <OK>. Om du vill scanna bilderna som en gemensam fil, tryck på <Dela upp i sidor> <Avbryt inställning>.
 För att välja PDF
För att välja PDF
|
1
|
Välj <PDF>
/b_D22500_C.gif)

OCR (Prioritera precision) kan inte användas om <Begränsad färg> eller <Konturer & utjämning> har valts med <OCR (Prioritera precision)>.
Om du väljer både <OCR (Prioritera precision)> och <Kompakt>, prioriteras inställningen <Bildkvalitetsnivå för Begränsad färg/Kompakt>. <Bildkvalitetsnivå för Begränsad färg/Kompakt>
Om du skapar en PDF-fil med både <OCR (Prioritera precision)> och <Kompakt> inställda, kan bildkvaliteten skilja sig från en PDF-fil som skapats med <OCR (Prioritera hastighet)> och <Kompakt> inställda.
Om du vill ändra språk för OCR, tryck på <OCR-språk>
Endast europeiska språk kan identifieras med <OCR (Prioritera precision)>. Inställningar och språk för OCR-bearbetning
|
För att välja XPS
|
1
|
Välj <XPS>
/b_D02128_C.gif)

Om du vill ändra språk för OCR, tryck på <OCR-språk>
|
För att välja Word-format för OOXML
|
1
|
Välj <OOXML>
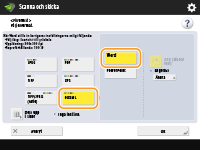

Om du vill ändra språk för OCR, tryck på <Ändra>
Välj ett språk eller en språkgrupp i enlighet med det språk som används i de scannade dokumenten.
|
För att välja PowerPoint-format för OOXML
|
1
|
Välj <OOXML>
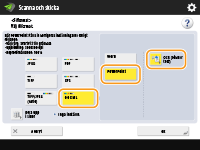
|
|
2
|
Välj språk som ska användas för OCR
|
6
Tryck på <OK>.

|
|
Långsmala original (432 mm eller längre) kan inte användas med <OCR (sökbar text)>.
|
|
|
|
Om du väljer <PDF (OCR)>, <XPS (OCR)> eller <OOXML (OCR)> som filformat och <Smart Scan> är inställt på <På> i <OCR (Text Searchable) Settings>/<OCR (Prioritera hastighet)>, identifieras originalets riktning automatiskt och det roteras vid behov innan det skickas. <Inställningar för OCR (sökbar text)>
Om du väljer <OCR (sökbar text)> kan du bara skicka med ett zoomförhållande på <1:1> eller <Auto>.
Om du väljer <PDF> eller <XPS> som filformat, kan du ange <Kompakt> och <OCR (sökbar text)> samtidigt. I detta fall visas <PDF (Kompakt)> eller <XPS (Kompakt)> som filformat i skärmbilden för grundläggande funktioner för scanna och skicka.
Om du väljer <Word> för <OOXML> kan du ange att ta bort de scannade bakgrundsbilderna. Du kan generera Word-filer som är enkla att redigera utan oönskade bilder. <Inkludera bakgrundsbilder I Word-fil>
Ifall du i dagsläget använder funktionen <Scanna och lagra> kan OCR-språket endast anges när <Word> är valt för <OOXML> eller <OCR (Prioritera precision)> är valt för <PDF>.
|
Otillfredsställande OCR-resultat
När du skapar textsökbara OOXML/PDF/XPS-filer, kanske inte OCR-bearbetningen (Optical Character Recognition) utförs ordentligt. Detta kan bero på att inställningar på maskinen, eller språket, teckentypen eller formatet på det ursprungliga dokumentet inte är lämpligt för OCR-bearbetning.
Kontrollera maskinens inställningar och språk som stöds
Du kan förbättra OCR-bearbetningen genom att anpassa maskinens inställningar för teckenigenkänning till originalet, eller genom att använda lämpliga teckentyper eller teckensnitt i originalet så att maskinen kan känna av tecknen.
Inställningar och språk för OCR-bearbetning
|
Egenskap
|
Detaljer
|
|
Språkinställningar för teckenigenkänning
|
När ett språk har angetts med OCR valt i <Filformat>:
Tecken identifieras baserat på det språk du väljer för respektive filformat. När ett språk inte har angetts med OCR valt i <Filformat>:
Tecken identifieras baserat på det språk du väljer i <Växla språk/tangentbord> (<Växla språk/tangentbord>).*1 |
|
Asiatiska språk som kan kännas igen*2
|
Japanska, kinesiska (förenklad), kinesiska (traditionell), koreanska
Teckentyper och teckensnitt som kan kännas igen (asiatiska språk) |
|
Europeiska språk och språkgrupper som kan kännas igen
|
Språk:
engelska, franska, italienska, tyska, spanska, nederländska, portugisiska, albanska, katalanska, danska, finska, isländska, norska, svenska, kroatiska, tjeckiska, ungerska, polska, slovakiska, estniska, lettiska, litauiska, ryska, grekiska, turkiska, slovenska *3, rumänska*3, bulgariska*3, hebreiska*3 Språkgrupper:
västeuropeiska (ISO)*4, centraleuropeiska (ISO)*5, baltiska (ISO)*6 Teckentyper och teckensnitt som kan kännas igen (europeiska språk) |
*1 Språken som visas i listan kan variera. Om du väljer engelska, franska, italienska, tyska, spanska, thailändska eller vietnamesiska, identifieras det valda språket som västeuropeiska (ISO).
*2 Asiatiska språk identifieras inte om <OCR (Prioritera precision)> har valts.
*3 Kan väljas bara med <OCR (Prioritera precision)>.
*4 Inklusive engelska, franska, italienska, tyska, spanska, nederländska, portugisiska, albanska, katalanska, danska, finska, isländska, norska och svenska.
*5 Inklusive kroatiska, tjeckiska, ungerska, polska och slovakiska.
*6 Inklusive estniska, lettiska och litauiska.
Teckentyper och teckensnitt som kan kännas igen (asiatiska språk)
|
Egenskap
|
Detaljer
|
|
Teckentyper som kan kännas igen
|
Japanska:
alfanumeriska tecken, Kana-tecken, kanji-tecken (första nivån av JIS och vissa av andra nivån av JIS), symboler Kinesiska (förenklad):
alfanumeriska tecken, kinesiska tecken, symboler (GB2312-80) Kinesiska (traditionell):
alfanumeriska tecken, kinesiska tecken, symboler (Big5) Koreanska:
alfanumeriska tecken, kinesiska tecken, Hangul-tecken, symboler (KSC5601) |
|
Teckensnitt som kan kännas igen
|
Flera teckensnitt stöds. (Ming-cho-typ rekommenderas.)
Kursiverade tecken kan inte identifieras.
|
|
Teckensnitt som används för konverterade tecken (endast om Word har valts som filformat)
|
Japanska:
asiatiska tecken: MS Mincho europeiska tecken: Century Kinesiska (förenklad):
asiatiska tecken: SimSun europeiska tecken: Calibri Kinesiska (traditionell):
asiatiska tecken: PMingLiU europeiska tecken: Calibri |
Teckentyper och teckensnitt som kan kännas igen (europeiska språk)
|
Egenskap
|
Detaljer
|
|
Teckentyper som kan kännas igen
|
Alfanumeriska tecken, specialtecken för det identifierade språket*1, symboler
|
|
Teckensnitt som kan kännas igen
|
Flera teckensnitt stöds. (Times, Century och Arial rekommenderas.)*2
Kursiverade tecken kan identifieras.
|
|
Teckensnitt som används för konverterade tecken (endast om Word har valts som filformat)
|
Calibri
Kursiv stil kan inte återskapas.
|
*1 Följande särskilda grekiska tecken kan identifieras. Specialtecken för varje språk kan också identifieras. Vissa specialtecken kan inte identifieras beroende på språk.
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ, υ, φ, χ, ψ, ω
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ, υ, φ, χ, ψ, ω
*2 Om <OCR (Prioritera precision)> har valts identifieras Arial, Times New Roman och Courier New.
Kontrollera originaldokumentets format
Använd original som är lämpliga för OCR-bearbetning för att förbättra bearbetningsresultatet när du skapar sökbara PDF/XPS/OOXML-filer.
|
Egenskap
|
Detaljer
|
|
Originalformat
|
Utskrivna dokument, ordbehandlingsdokument (dokument som består av text, grafik, fotografier eller tabeller, och utan lutande tecken)
|
|
Textformat
|
Horisontell och vertikal skrift (dokument som innehåller både horisontell och vertikal skrift kan kännas igen)
Bara horisontell skrift kan kännas igen för europeiska språk och koreansk text.
Dokument med en till tre spalter utan komplexa spaltinställningar
|
|
Teckenstorlek
|
8 till 40 punkter
|
|
Tabellformat (endast för Word-format)
|
Tabeller som uppfyller följande villkor:
Tabeller bestående av rutor indelade med fasta linjer
Tabeller med upp till 32 kolumner
Tabeller med upp till 32 rader
|
|
|
Vissa original som är lämpliga för OCR-bearbetning kanske inte behandlas på rätt sätt.Hög noggrannhet kanske inte kan uppnås med original som innehåller en stor mängd text på varje sida.
Tecken kan ersättas med fel tecken eller saknas på grund av bakgrundsfärgen på originalet, form och storlek för tecken, eller lutande tecken.*
Stycken, radbrytningar eller tabeller kanske inte återskapas.*
Vissa delar av illustrationer, fotografier och stämplar kan identifieras som tecken och ersättas med tecken.*
* När Word är valt som filformat.
|