OCR 기능으로 스캔
 | 이 모드를 사용하면 OCR(광학 문자 인식)을 수행하여 스캔한 이미지에서 텍스트로 인식할 수 있는 데이터를 추출하여 검색 가능한 PDF/XPS/OOXML(pptx/docx) 파일을 만들 수 있습니다. 또한 파일 형식으로 PDF 또는 XPS를 선택한 경우 <고압축>을 설정할 수도 있습니다. 이 기능과 파일 형식을 사용하기 위해 필요한 옵션 제품에 대한 내용은 시스템 옵션을(를) 참조하십시오. |
OCR 기능으로 스캔
1
원고를 넣으십시오. 원고 올려 놓기
2
<스캔하고 송신>를 누릅니다. <메인 메뉴> 화면
3
스캔 기본 기능 화면에서 수신인을 지정하십시오. 스캔 기본 기능 화면
4
필요에 따라 스캔 설정을 지정합니다.원고 스캔 기본 작업
5
파일 형식을 선택합니다.
여러 이미지를 분리하여 단일 페이지로만 구성된 개별 파일로 전송하려면 <페이지마다 분할>  을 누르고 별로 나눌 페이지 수를 입력한 후 <확인>을 누릅니다. 이미지를 단일 파일로 스캔하려면 <페이지마다 분할> <설정 취소>를 누릅니다.
을 누르고 별로 나눌 페이지 수를 입력한 후 <확인>을 누릅니다. 이미지를 단일 파일로 스캔하려면 <페이지마다 분할> <설정 취소>를 누릅니다.
 PDF를 선택하려면
PDF를 선택하려면
1 | <PDF>를 선택하고   OCR (유럽문자 인식)은 <소수색> 또는 <아웃라인>을 <OCR (유럽문자 인식)>과 함께 선택한 경우 수행할 수 없습니다. <OCR (유럽문자 인식)> 및 <고압축>을 모두 설정한 경우 <고압축/소수색 시 화질레벨> 설정이 비활성화됩니다. <고압축/소수색 시 화질레벨> <OCR (유럽문자 인식)> 및 <고압축> 모두 설정된 상태에서 PDF 파일을 생성할 경우 화질이 <OCR (문자인식)> 및 <고압축>이 설정된 상태에서 생성된 PDF 파일과 다를 수 있습니다. OCR에 사용할 언어를 변경하려면 <OCR 언어>를 누르고 유럽 언어만 <OCR (유럽문자 인식)>에서 감지할 수 있습니다. OCR 처리를 위한 설정 및 언어 |
XPS를 선택하려면
1 | <XPS>를 선택하고  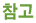 OCR에 사용할 언어를 변경하려면 <OCR 언어>를 누르고 |
OOXML에 대해 Word 형식을 선택하는 방법
1 | <OOXML>  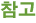 OCR에 사용할 언어를 변경하려면 <변경>을 누르고 스캔한 문서에 사용되는 언어에 따라 하나의 언어 또는 언어 그룹을 선택합니다. |
OOXML에 대해 PowerPoint 형식을 선택하는 방법
1 | <OOXML>  |
2 | OCR에 사용할 언어 선택 |
6
<확인>를 누릅니다.
 |
스트립이 긴 원고(432 mm 이상)는 <OCR (문자인식)>에서 사용할 수 없습니다. |
|
<PDF (OCR)>, <XPS (OCR)> 또는 <OOXML (OCR)>을 파일 형식으로 선택하고 <원고방향 자동검지>를 <OCR (문자인식) 설정>에서 <설정>으로 설정한 경우 원고의 방향이 감지되고, 필요한 경우 전송되기 전에 문서가 자동으로 회전됩니다. <OCR (문자인식) 설정> <OCR (문자인식)>을 선택하면 <1:1> 또는 <Auto>의 확대/축소 비율에서만 전송할 수 있습니다. <PDF> 또는 <XPS>를 파일 형식으로 선택하면 <고압축> 및 <OCR (문자인식)>을 동시에 설정할 수 있습니다. 이 경우 <PDF (고압축)> 또는 <XPS (고압축)>이 스캔 및 전송 기본 기능 화면에서 파일 형식으로 표시됩니다. <Word>를 <OOXML>에 대해 선택할 경우 스캔한 배경 이미지를 삭제하도록 설정할 수 있습니다. 원치 않는 이미지 없이 쉽게 편집되는 Word 파일을 만들 수 있습니다. <Word 파일에 배경화상을 포함> 현재 <스캔하고 저장> 기능을 사용 중인 경우 <Word>를 <OOXML>에서 선택하거나 <OCR (유럽문자 인식)>을 <PDF>에서 선택한 경우에만 OCR 언어를 지정할 수 있습니다. |
OCR 결과가 만족스럽지 않은 경우
텍스트 검색 가능한 PDF/XPS/OOXML 파일을 생성하는 경우 OCR(광학 문자 인식) 기능이 제대로 처리되지 않을 수 있습니다. 이것은 기기 설정 문제일 수도 있고 원본 문서의 언어, 글자 유형 또는 서식이 OCR 처리에 부적절해서일 수도 있습니다.
기기 설정 및 지원되는 언어 확인
OCR 처리 기능을 개선하려면 원고에 따라 글자 인식에 관한 기기 설정을 사용자 지정하거나, 원고에서 적절한 글자 유형 또는 글꼴을 사용하여 기기가 글자를 인식할 수 있게 해주면 됩니다.
OCR 처리를 위한 설정 및 언어
항목 | 자세히 |
글자 인식을 위한 언어 설정 | <파일 형식>에서 OCR을 선택한 상태에서 언어를 지정할 경우: 문자가 각 파일 형식에 대해 선택한 언어를 기준으로 인식됩니다. |
인식 가능한 아시아 언어*2 | 일본어, 중국어(간체), 중국어(번체), 한국어 인식 가능한 글자 유형 및 글꼴(아시아 언어) |
인식 가능한 유럽 언어 및 언어권 | 언어: 영어, 프랑스어, 이탈리아어, 독일어, 스페인어, 네덜란드어, 포르투갈어, 알바니아어, 카탈로니아어, 덴마크어, 핀란드어, 아이슬란드어, 노르웨이어, 스웨덴어, 크로아티아어, 체코어, 헝가리어, 폴란드어, 슬로바키아어, 에스토니아어, 라트비아어, 리투아니아어, 러시아어, 그리스어, 터키어, 슬로베니아어*3, 루마니아어*3, 불가리아어*3, 히브리어*3 |
*1 목록에 표시되는 언어는 각기 다를 수 있습니다. 영어, 프랑스어, 이탈리아어, 독일어, 스페인어, 태국어 또는 베트남어를 선택하는 경우 선택한 언어는 서유럽(ISO)으로 인식됩니다.
*2 아시아 언어는 <OCR (유럽문자 인식)>을 선택한경우 감지될 수 없습니다.
*3 이 항목은 <OCR (유럽문자 인식)>에서만 선택할 수 있습니다.
*4 영어, 프랑스어, 이탈리아어, 독일어, 스페인어, 네덜란드어, 포르투갈어, 알바니아어, 카탈로니아어, 덴마크어, 아이슬란드어, 노르웨이어 및 스웨덴어 포함.
*5 크로아티아어, 체코어, 헝가리어, 폴란드어 및 슬로바키아어 포함.
*6 에스토니아어, 라트비아어 및 리투아니아어 포함.
인식 가능한 글자 유형 및 글꼴(아시아 언어)
항목 | 자세히 |
인식 가능한 글자 유형 | 일본어: 영숫자, 카타가나, 한자(JIS 1급 및 JIS 2급 일부), 기호 중국어(간체): 영숫자, 한자, 기호(GB2312-80) 중국어(번체): 영숫자, 한자, 기호(Big5) 한국어: 영숫자, 한자, 한글 문자, 기호(KSC5601) |
인식 가능한 글꼴 | 여러 가지 글꼴이 지원됩니다(Ming-cho 유형을 권장합니다). 기울임꼴 글자는 인식할 수 없습니다. |
변환된 문자에 사용되는 글꼴(파일 서식이 Word로 선택된 경우만 해당) | 일본어: 아시아 글자: MS Mincho 유럽 글자: Century 중국어(간체): 아시아 글자: SimSun 유럽 글자: Calibri 중국어(번체): 아시아 글자: PMingLiU 유럽 글자: Calibri |
인식 가능한 글자 유형 및 글꼴(유럽 언어)
항목 | 자세히 |
인식 가능한 글자 유형 | 영숫자, 인식 가능한 언어의 특수 문자*1, 기호 |
인식 가능한 글꼴 | 여러 가지 글꼴이 지원됩니다(Times, Century 및 Arial을 권장합니다)*2 기울임꼴 글자를 인식할 수 있습니다. |
변환된 문자에 사용되는 글꼴(파일 서식이 Word로 선택된 경우만 해당) | Calibri 기울임 스타일은 재현되지 않습니다. |
*1 다음 그리스 특수 문자는 인식할 수 있습니다. 각 언어의 특수 문자도 인식할 수 있습니다. 언어에 따라 일부 특수 문자를 인식할 수 없는 경우도 있습니다.
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ,υ, φ, χ, ψ, ω
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ,υ, φ, χ, ψ, ω
*2 <OCR (유럽문자 인식)>을 선택할 경우 Arial 유형, Times New Roman 유형 및 Courier New 유형 글꼴이 인식됩니다.
원본 문서의 서식 확인
OCR 처리에 적합한 원고를 사용해야 검색 가능한 PDF/XPS/OOXML 파일을 생성할 때 처리 정확도를 개선할 수 있습니다.
항목 | 자세히 |
원고 형식 | 인쇄된 문서, 워드 프로세서 문서(텍스트, 그래픽, 사진 또는 표로 구성되었으며 글자 기울기가 없는 문서) |
텍스트 서식 | 가로쓰기 및 세로쓰기(가로쓰기와 세로쓰기가 둘 다 들어있는 문서도 인식) 유럽 언어와 한국어 텍스트의 경우 가로쓰기만 인식됩니다. 열이 1~3개인 문서로 열 설정이 복잡하지 않은 것 |
글자 크기 | 8~40 포인트 |
표 서식(Word 서식에만 해당) | 다음 조건에 부합하는 표만 해당됩니다. 실선으로 분할된 정사각형으로 구성된 표 열 수가 최대 32개인 표 행 수가 최대 32개인 표 |
|
OCR 처리에 적합한 원고라도 제대로 처리되지 않는 경우가 일부 있습니다.페이지마다 텍스트 양이 많은 원고 등 몇몇 경우에는 정확도가 높지 않습니다. 원고의 배경색, 글자의 형태와 크기 또는 기울어진 글자 등의 이유로 글자가 의도치 않은 다른 글자로 대체되거나 누락될 수 있습니다.* 단락, 줄바꿈 또는 표가 재현되지 않을 수 있습니다.* 삽화, 사진 또는 낙인 중에는 일부 글자로 인식되어 다른 글자로 대체되는 경우가 있을 수 있습니다.* * 파일 서식이 Word로 선택된 경우입니다. |