Scanning with the OCR Function
 | This mode enables you to perform OCR (optical character recognition) to extract data that can be recognized as text from the scanned image and create a PDF/OOXML (pptx/docx) file that is searchable. You can also set <Compact> if you select PDF as the file format. For information on the optional products required to use this function and the file formats, see System Options. |
Scanning with OCR
1
Place the original. Placing Originals
2
Press <Scan and Send>. <Home> Screen
3
Specify the destination on the Scan Basic Features screen. Scan Basic Features Screen
4
Specify the scan settings as necessary. Basic Operations for Scanning Originals
5
Select a file format.
If you want to separate multiple images and send them as separate files, each of which consists of only one page, press <Divide into Pages>  enter the number of pages to divide by press <OK>. If you want to scan the images as a single file, press <Divide into Pages> <Cancel Settings>.
enter the number of pages to divide by press <OK>. If you want to scan the images as a single file, press <Divide into Pages> <Cancel Settings>.
 To select PDF
To select PDF
1 | Select <PDF>   OCR (Prioritize Precision) cannot be performed if <Limited Color> or <Trace & Smooth> is selected with <OCR (Prioritize Precision)>. If you set both <OCR (Prioritize Precision)> and <Compact>, the <Image Quality Level for Limited Color/Compact> setting is disabled. <Image Quality Level for Limited Color/Compact> If you create a PDF file with both <OCR (Prioritize Precision)> and <Compact> set, the image quality may differ from a PDF file created with <OCR (Prioritize Speed)> and <Compact> set. To change a language to use for OCR, press <OCR Language> Only European languages can be detected with <OCR (Prioritize Precision)>. Settings and Languages for OCR Processing |
To select the Word format for OOXML
1 | Select <OOXML> 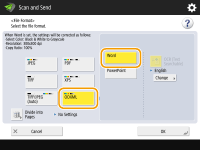  To change a language to use for OCR, press <Change> Select a language or language group according to the language used in the scanned documents. |
To select the PowerPoint format for OOXML
1 | Select <OOXML> 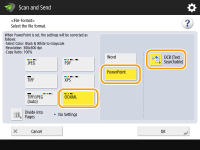 |
2 | Select a language to use for OCR |
6
Press <OK>.
 |
Long strip originals (25 1/4" (432 mm) or longer) cannot be used with <OCR (Text Searchable)>. |
|
If you select <PDF (OCR)> or <OOXML (OCR)> as the file format, and <Smart Scan> is set to <On> in <OCR (Text Searchable) Settings>/<OCR (Prioritize Speed)>, the orientation of the original is detected, and the document is automatically rotated if necessary before it is sent. <OCR (Text Searchable) Settings> If you select <OCR (Text Searchable)>, you can only send at a zoom ratio of <Direct>/<1:1> or <Auto>. If you select <PDF> as the file format, you can set <Compact> and <OCR (Text Searchable)> at the same time. In that case, <PDF (Compact)> is displayed as the file format on the Scan and Send Basic Features screen. If you select <Word> for <OOXML>, you can set to delete the scanned background images. You can generate Word files which are easy to edit without unwanted images. <Include Background Images in Word File> If you are currently using the <Scan and Store> function, the OCR language can only be specified when <Word> is selected for <OOXML> or <OCR (Prioritize Precision)> is selected for <PDF>. |
OCR Results Are Not Satisfactory
When you create text-searchable PDF/OOXML files, OCR (Optical Character Recognition) may not be properly processed. This may be because the settings on the machine, or the language, character type or format of the original document are not appropriate for OCR processing.
Checking the Machine Settings and Supported Languages
You can improve OCR processing by customizing the machine settings regarding character recognition according to the originals, or by using suitable character types or fonts in the originals so that the machine can recognize the characters.
Settings and Languages for OCR Processing
Item | Details |
Language Settings for Character Recognition | When a language is specified with OCR selected in <File Format>: Characters are recognized based on the language you select for each file format. When a language is not specified with OCR selected in <File Format>: Characters are recognized based on the language you select in <Switch Language/Keyboard> (<Switch Language/Keyboard>).*1 |
Recognizable Asian Languages*2 | Japanese, Chinese (Simplified), Chinese (Traditional), Korean Recognizable Character Types and Fonts (Asian Languages) |
Recognizable European Languages and Language Groups | Languages: English, French, Italian, German, Spanish, Dutch, Portuguese, Albanian, Catalan, Danish, Finnish, Icelandic, Norwegian, Swedish, Croatian, Czech, Hungarian, Polish, Slovak, Estonian, Latvian, Lithuanian, Russian, Greek, Turkish, Slovenian*3, Romanian*3, Bulgarian*3, Hebrew*3 Language Groups: Western European (ISO)*4, Central European (ISO)*5, Baltic (ISO)*6 Recognizable Character Types and Fonts (European Languages) |
*1 Displayed languages in the list may vary. If you select English, French, Italian, German, Spanish, Thai, or Vietnamese, the selected language is recognized as Western European (ISO).
*2 Asian languages cannot be detected when <OCR (Prioritize Precision)> is selected.
*3 This can only be selected with <OCR (Prioritize Precision)>.
*4 Including English, French, Italian, German, Spanish, Dutch, Portuguese, Albanian, Catalan, Danish, Finnish, Icelandic, Norwegian, and Swedish.
*5 Including Croatian, Czech, Hungarian, Polish, and Slovak.
*6 Including Estonian, Latvian, and Lithuanian.
Recognizable Character Types and Fonts (Asian Languages)
Item | Details |
Recognizable Character Types | Japanese: Alphanumeric characters, Kana characters, Kanji characters (JIS first level, and some of the JIS second level), Symbols Chinese (Simplified): Alphanumeric characters, Chinese characters, Symbols (GB2312-80) Chinese (Traditional): Alphanumeric characters, Chinese characters, Symbols (Big5) Korean: Alphanumeric characters, Chinese characters, Hangul characters, Symbols (KSC5601) |
Recognizable Fonts | Multiple fonts are supported. (Ming-cho type is recommended.) Italicized characters cannot be recognized. |
Fonts Used for Converted Characters (Only when Word is selected as the file format) | Japanese: Asian characters: MS Mincho European characters: Century Chinese (Simplified): Asian characters: SimSun European characters: Calibri Chinese (Traditional): Asian characters: PMingLiU European characters: Calibri |
Recognizable Character Types and Fonts (European Languages)
Item | Details |
Recognizable Character Types | Alphanumeric characters, Special characters of the recognized language*1, Symbols |
Recognizable Fonts | Multiple fonts are supported. (Times, Century, and Arial are recommended.)*2 Italicized characters can be recognized. |
Fonts Used for Converted Characters (Only when Word is selected as the file format) | Calibri Italic style is not reproduced. |
*1 The following special Greek characters can be recognized. Special characters for each language can also be recognized. Some special characters cannot be recognized depending on the languages.
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ,υ, φ, χ, ψ, ω
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ,υ, φ, χ, ψ, ω
*2 When <OCR (Prioritize Precision)> is selected, Arial type, Times New Roman type, and Courier New type fonts are recognized.
Checking the Format of the Original Documents
Use originals suitable for OCR processing to improve the processing accuracy when creating searchable PDF/OOXML files.
Item | Details |
Original Format | Printed documents, Word processor documents (documents consisting of text, graphics, photographs, or tables, and with no character slant) |
Text Format | Horizontal and vertical writing (documents containing both horizontal and vertical writing can also be recognized) Only horizontal writing can be recognized for European languages and Korean text. One to three column documents with no complex column settings |
Character Size | 8 to 40 point |
Table Format (For Word Format Only) | Tables that meet the following conditions: Tables consist of squares divided with solid lines Tables with up to 32 columns Tables with up to 32 rows |
|
Some originals suitable for OCR processing may not be processed properly.High accuracy may not be achieved with originals including a large amount of text on each page. Characters may be replaced with unintended characters or be missing due to the background color of the original, form and size of characters, or slanted characters.* Paragraphs, line breaks, or tables may not be reproduced.* Some parts of illustrations, photographs, or seal impressions may be recognized as characters and be replaced with characters.* * When Word is selected as the file format. |