Numérisation avec la fonction OCR
 | Ce mode vous permet d'exécuter l'OCR (optical character recognition) pour extraire les données qui peuvent être reconnues comme texte de l'image numérisée et de créer un fichier PDF/OOXML (pptx/docx) qui est interrogeable. Vous pouvez aussi définir <Compact> si vous sélectionnez PDF comme format de fichier. Pour en savoir plus sur les produits en option requis pour utiliser cette fonction et les formats de fichiers, consultez la section Options du système |
Numérisation avec la fonction OCR
1
Mettez l'original en place. Placement des documents
2
Appuyez sur <Lire et Envoyer>. Écran <Accueil>
3
Spécifiez la destination sur l'écran Fonctions de base de numérisation. Ecran Fonctions de base de numérisation
4
Spécifiez les paramètres de numérisation si nécessaire. Opérations de base pour numériser des documents
5
Sélectionnez un format de fichier.
Si vous voulez séparer plusieurs images et les envoyer comme des fichiers séparés, chacun étant composé d'une seule page, appuyez sur <Scinder en plsrs pages>  saisissez le nombre de pages à diviser par , puis appuyez sur <OK>. Si vous voulez numériser les images comme fichier unique, appuyez sur <Scinder en plsrs pages> <Annuler réglages>.
saisissez le nombre de pages à diviser par , puis appuyez sur <OK>. Si vous voulez numériser les images comme fichier unique, appuyez sur <Scinder en plsrs pages> <Annuler réglages>.
 Pour sélectionner PDF
Pour sélectionner PDF
1 | Sélectionnez <PDF> 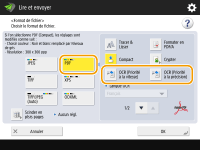  OCR (Priorité à la précision) ne peut être exécutée si <Tracer & Lisser> est sélectionné avec <OCR (Priorité à la précision)>. Si vous spécifiez <OCR (Priorité à la précision)> et <Compact>, le réglage <Niveau de qualité image pour Compact> est désactivé. <Niveau de qualité image pour Compact> Si vous créez un fichier avec les options <OCR (Priorité à la précision)> et <Compact> définies, la qualité d'image peut être différente de celle d'un fichier PDF créé avec les options <OCR (Priorité à la vitesse)> et <Compact> définies. Pour modifier une langue pour utiliser l'OCR, appuyez sur <OCR Language> Seules les langues européennes peuvent être détectées avec <OCR (Priorité à la précision)>. Réglages et langues du traitement OCR |
Pour sélectionner le format Word pour OOXML
1 | Sélectionnez <OOXML> 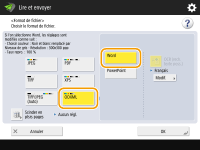  Pour modifier une langue pour utiliser l'OCR, appuyez sur <Modifier> Sélectionnez une langue ou un groupe de langues en fonction de la langue utilisée dans les documents numérisés. |
Pour sélectionner le format PowerPoint pour OOXML
1 | Sélectionnez <OOXML> 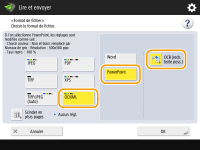 |
2 | Sélectionnez une langue pour l'OCR |
6
Appuyez sur <OK>.
 |
Les originaux très longs (432 mm (25 1/4") ou plus) ne peuvent pas être utilisés avec <OCR (rech. texte possible)>. |
|
Si vous sélectionnez <PDF (OCR)> ou <OOXML (OCR)> comme format de fichier, et <Lecture avancée> est défini sur <Oui> dans <Réglages OCR (recherche de texte possible)>/<OCR (Priorité à la vitesse)>, l'orientation de l'original est détectée et le document est automatiquement tourné si nécessaire avant qu'il ne soit envoyé. <Réglages OCR (recherche texte possible)> Si vous sélectionnez <OCR (rech. texte possible)>, vous ne pouvez envoyer qu'à un taux de reproduction de <Direct>/<1:1> ou <Auto>. Si vous sélectionnez <PDF> comme format de fichier, vous pouvez définir <Compact> et <OCR (rech. texte possible)> en même temps. Dans ce cas, <PDF (Compact)> s'affiche comme format de fichier sur l'écran des fonctions de base pour l'envoi et la numérisation. Si vous sélectionnez <Word> pour <OOXML>, vous pouvez définir la suppression des images de fond numérisées. Vous pouvez générer des fichiers Word qui sont simples à éditer sans les images non souhaitées. <Inclure images de fond dans le fichier Word> Si vous utilisez actuellement la fonction <Lire et mémoriser>, vous ne pouvez spécifier la langue OCR que si <Word> est sélectionné pour <OOXML> ou <OCR (Priorité à la précision)> est sélectionné pour <PDF>. |
Les résultats de l'OCR ne sont pas satisfaisants
Lorsque vous créez des fichiers PDF ou OOXML interrogeables, il se peut que la reconnaissance optique de caractères (OCR) ne s'effectue pas correctement. Cela peut s'expliquer par le fait que les réglages de l'appareil, la langue, le type de caractère ou le format du document original ne sont pas adaptés au traitement OCR.
Vérification des réglages de l'appareil et des langues prises en charge
Vous pouvez améliorer le traitement OCR en adaptant aux originaux les réglages de l'appareil en matière de reconnaissance de caractères ou en utilisant dans ces originaux des polices ou des types de caractère adaptés aux fonctions de reconnaissance de l'appareil.
Réglages et langues du traitement OCR
Élément | Détails |
Réglages linguistiques de la reconnaissance de caractères | Lorsqu'une langue est spécifiée avec l'OCR sélectionné dans <Format de fichier> : les caractères sont reconnus d'après la langue que vous sélectionnez pour chaque format de fichier. Lorsqu'une langue n'est pas spécifiée avec l'OCR sélectionné dans <Format de fichier> : les caractères sont reconnus d'après la langue que vous sélectionnez dans <Changer langue/clavier> (<Changer langue/clavier>).*1 |
Langues asiatiques prises en charge*2 | Japonais, chinois (simplifié), chinois (traditionnel), coréen Polices et types de caractères pris en charge (langues asiatiques) |
Langues européennes et groupes de langues pris en charge | Langues : anglais, français, italien, allemand, espagnol, néerlandais, portugais, albanais, catalan, danois, finnois, islandais, norvégien, suédois, croate, tchèque, hongrois, polonais, slovaque, estonien, letton, lituanien, russe, grec, turc, slovène*3, roumain*3, bulgare*3, hébreu*3 Groupes de langues : Europe de l'Ouest (ISO)*4, Europe centrale (ISO)*5, Balte (ISO)*6 Polices et types de caractères pris en charge (langues européennes) |
*1 Les langues affichées dans la liste peuvent varier. Si vous sélectionnez l'anglais, le français, l'italien, l'allemand, l'espagnol, le thaï ou le vietnamien, la langue sélectionnée est reconnue comme étant une langue d'Europe de l'Ouest (ISO).
*2 Les langues asiatiques ne peuvent être détectées lorsque <OCR (Priorité à la précision)> est sélectionné.
*3 Ces langues ne peuvent être sélectionnées qu'avec l'option <OCR (Priorité à la précision)>.
*4 Langues incluses : anglais, français, italien, allemand, espagnol, néerlandais, portugais, albanais, catalan, danois, finnois, islandais, norvégien et suédois.
*5 Langues incluses : croate, tchèque, hongrois, polonais et slovaque.
*6 Langues incluses : estonien, letton et lituanien.
Polices et types de caractères pris en charge (langues asiatiques)
Elément | Détails |
Types de caractères pris en charge | Japonais : Caractères alphanumériques, kana, kanji (JIS de niveau 1 et, partiellement, JIS de niveau 2), symboles Chinois (simplifié) : Caractères alphanumériques, caractères chinois, symboles (GB2312-80) Chinois (traditionnel) : Caractères alphanumériques, caractères chinois, symboles (Big5) Coréen : Caractères alphanumériques, caractères chinois, hangeul, symboles (KSC5601) |
Polices prises en charge | Plusieurs polices sont prises en charge. (Le type Ming-cho est recommandé.) Les caractères composés en italique ne sont pas pris en charge. |
Polices employées pour les caractères convertis (uniquement si Word est sélectionné en tant que format de fichier) | Japonais : Caractères asiatiques : MS Mincho Caractères européens : Century Chinois (simplifié) : Caractères asiatiques : SimSun Caractères européens : Calibri Chinois (traditionnel) : Caractères asiatiques : PMingLiU Caractères européens : Calibri |
Polices et types de caractères pris en charge (langues européennes)
Elément | Détails |
Types de caractères pris en charge | Caractères alphanumériques, caractères spéciaux de la langue reconnue*1, symboles |
Polices prises en charge | Plusieurs polices sont prises en charge. (Les polices Times, Century et Arial sont recommandées.)*2 Les caractères composés en italique sont pris en charge. |
Polices employées pour les caractères convertis (uniquement si Word est sélectionné en tant que format de fichier) | Calibri L'écriture italique n'est pas reproduite. |
*1 Les caractères grecs ci-après sont pris en charge, ainsi que les caractères spéciaux propres à chaque langue. Selon les langues, certains caractères spéciaux ne sont pas reconnus.
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ, υ, φ, χ, ψ, ω
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ, υ, φ, χ, ψ, ω
*2 Lorsque <OCR (Priorité à la précision)> est sélectionné, les polices de types Arial, Times New Roman et Courier New sont reconnues.
Vérification du format des documents originaux
Lorsque vous créez des fichiers PDF ou OOXML interrogeables, utilisez des originaux adaptés à la reconnaissance optique de caractères afin d'accroître la précision du traitement.
Elément | Détails |
Format original | Documents imprimés ou documents Word (comportant du texte, des graphiques, des photographies ou des tableaux, mais sans caractères inclinés) |
Format du texte | Ecriture horizontale et verticale (les documents comportant du texte à l'horizontale et à la verticale sont également pris en charge) Pour les langues européennes et les textes coréens, seule est reconnue l'écriture horizontale. Documents comportant une à trois colonnes sans réglages de colonne complexes |
Taille des caractères | 8 à 40 points |
Format des tableaux (format Word uniquement) | Tableaux remplissant les critères suivants : Tableaux composés de carrés séparés par des lignes pleines Tableaux comportant jusqu'à 32 colonnes Tableaux comportant jusqu'à 32 lignes |
|
Il est possible que certains originaux pourtant adaptés à la reconnaissance optique de caractères ne soient pas traités correctement.Il est possible que vous ne puissiez pas obtenir une précision élevée avec les originaux comportant un gros volume de texte sur chaque page. Les caractères peuvent manquer ou être remplacés par des caractères indésirables en raison de la couleur d'arrière-plan de l'original ou encore de la forme, de la taille et de l'inclinaison des caractères.* Les paragraphes, les sauts de ligne ou les tableaux ne peuvent pas être reproduits.* Il est possible que certaines parties des illustrations, des photographies ou des cachets soient reconnues comme des caractères et qu'elles soient remplacées par des caractères.* * Si Word est sélectionné en tant que format de fichier. |