使用 OCR 功能进行扫描
 | 该模式下可以执行OCR(光学字符识别)从已扫描的图像中提取可识别为文本的数据并创建可搜索的PDF/XPS/OOXML (pptx/docx)文件。如果选择PDF 或 XPS作为文件格式,也可以设置<压缩>。 |
使用 OCR 进行扫描
1
放置原稿。 放置文档
2
按 <扫描后发送>。<主页>屏幕
3
在“基本扫描功能”屏幕上指定接收方。基本扫描功能屏幕
4
根据需要指定扫描设置。 扫描原稿的基本操作
5
选择文件格式。
如果要分离多个图像并作为单独文件发送(每个文件仅有一页),按<分割为多页>  输入要分割的页数 ,然后按 <确定>。如果要将图像扫描为单一文件,按<分割为多页> <取消设置>。
输入要分割的页数 ,然后按 <确定>。如果要将图像扫描为单一文件,按<分割为多页> <取消设置>。
 选择PDF
选择PDF
1 | 选择<PDF>  如果通过<OCR(欧洲语言)>选择了<轮廓>,OCR(欧洲语言)无法执行。 如果同时设置了<OCR(欧洲语言)>和<压缩>,则<压缩的图像质量优先级>设置禁用。<压缩的图像质量优先级> 如果在设置<OCR(欧洲语言)>和<压缩>的同时创建了PDF文件,图像质量可能与设置了<OCR(可检索文本)>和<压缩>创建的PDF文件有所不同。 要更改OCR所用的语言,按<OCR语言> 通过<OCR(欧洲语言)>只能检测到欧洲语言。OCR处理的设置和语言 |
选择XPS
1 | 选择<XPS>  要更改OCR所用的语言,按<OCR语言> |
选择 OOXML 的 Word 格式
1 | 选择<OOXML>  要更改 OCR 所用的语言,按<更改> 根据已扫描的文档中使用的语言选择语言或语言组。 |
选择 OOXML 的 PowerPoint 格式
1 | 选择<OOXML> |
2 | 选择OCR所用的语言 |
6
按<确定>。
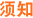 |
长条原稿(432 mm 或更长)不能与<OCR(可检索文本)>一起使用。 |
|
如果选择<PDF(OCR)>、<XPS(OCR)>、或<OOXML(OCR)>作为文件格式,而且在<OCR(可检索文本)设置>中将<智能扫描> 设为<打开>,将检测出原稿方向,如有必要可以在发送文档之前将其自动旋转。<OCR(可检索文本)设置> 如果选择<OCR(可检索文本)>,可以仅以<1:1> 或 <Auto>倍率发送。 如果选择<PDF>或<XPS>作为文件格式,可以同时设置<压缩> 和<OCR(可检索文本)>。在这种情况下,<PDF(压缩)> 或<XPS(压缩)>将作为文件格式显示在“扫描并发送基本功能”屏幕上。 如果为<OOXML>选择<Word>,可以进行设置来删除已扫描的背景图像。可以生成易于编辑且没有多余图像的Word文件。<Word文件中包含背景图像> 如果正在使用<扫描后存储>功能,则仅当为<OOXML>选择<Word>或者为<PDF>选择<OCR(欧洲语言)>时,方可指定OCR语言。 |
OCR结果不理想
当创建“文本可检索PDF/XPS/OOXML”文件时,OCR(光学字符识别)可能无法正确处理。原因可能是本机设置或原稿的语言、字符类型或原稿格式不适合进行OCR处理。
检查本机设置和支持的语言
可以根据原稿自定义本机在字符识别方面的设置,或在原稿中使用合适的字符类型或字体以便本机识别字符,从而改进OCR处理。
OCR处理的设置和语言
项目 | 详细说明 |
字符识别的语言设置 | 通过在<文件格式>中选择的OCR指定语言时: 根据您为每种文件格式选择的语言来识别字符。 |
可识别的亚洲语言*2 | 日语、中文(简体)、中文(繁体)、韩语 可识别的字符类型和字体(亚洲语言) |
可识别的欧洲语言和语族 | 语言: 英语、法语、意大利语、德语、西班牙语、荷兰语、葡萄牙语、阿尔巴尼亚语、加泰罗尼亚语、丹麦语、芬兰语、冰岛语、挪威语、瑞典语、克罗地亚语、捷克语、匈牙利语、波兰语、斯洛伐克语、爱沙尼亚语、拉脱维亚语、立陶宛语、俄语、希腊语、土耳其语、斯洛文尼亚语*3、罗马尼亚语*3、保加利亚语*3、希伯来语*3 |
*1 列表中显示的语言可能有所差异。如果选择“English”(英语)、“French”(法语)、“Italian”(意大利语)、“German”(德语)、“Spanish”(西班牙语)、“Thai”(泰语)或“Vietnamese”(越南语),则选择的语言会被识别为“Western European (ISO)(西欧语言(ISO))”。
*2选择<OCR(欧洲语言)>后,无法检测到亚洲语言。
*3 只能与<OCR(欧洲语言)>一起选择。
*4 包括“English”(英语)、“French”(法语)、“Italian(”意大利语)、“German”(德语)、“Spanish”(西班牙语)、“Dutch”(荷兰语)、“Portuguese”(葡萄牙语)、“Albanian”(阿尔巴尼亚语)、“Catalan”(加泰罗尼亚语)、“Danish”(丹麦语)、“Finnish”(芬兰语)、“Icelandic”(冰岛语)、“Norwegian”(挪威语)和“Swedish”(瑞典语)。
*5 包括“Croatian”(克罗地亚语)、“Czech”(捷克语)、“Hungarian”(匈牙利语)、“Polish”(波兰语)和“Slovak”(斯洛伐克语)。
*6 包括“Estonian”(爱沙尼亚语)、“Latvian”(拉脱维亚语)和“Lithuanian”(立陶宛语)。
可识别的字符类型和字体(亚洲语言)
项目 | 详细说明 |
可识别的字符类型 | 日语: 字母数字字符、假名字符、汉字字符(JIS first level、部分JIS second level)、符号 中文(简体): 字母数字字符、中文字符、符号(GB2312-80) 中文(繁体): 字母数字字符、中文字符、符号(Big5) 韩语: 字母数字字符、汉字字符、韩语字符、符号(KSC5601) |
可识别的字体 | 支持多种字体。(推荐Ming-cho类型。) 无法识别斜体字符。 |
用于转换字符的字体(仅在Word选择为文件格式时) | 日语: 亚洲语言字符:MS Mincho 欧洲语言字符:Century 中文(简体): 亚洲语言字符:SimSun 欧洲语言字符:Calibri 中文(繁体): 亚洲语言字符:PMingLiU 欧洲语言字符:Calibri |
可识别的字符类型和字体(欧洲语言)
项目 | 详细说明 |
可识别的字符类型 | 字母数字字符、所识别语言的特殊字符*1、符号 |
可识别的字体 | 支持多种字体。(推荐Times、Century和Arial。)*2 可识别斜体字符。 |
用于转换字符的字体(仅在Word选择为文件格式时) | Calibri 不复制Italic样式。 |
*1 可以识别以下特殊希腊语字符。也可以识别每种语言的特殊字符。根据不同的语言,无法识别某些特殊字符。
Α、Β、Γ、Δ、Ε、Ζ、Η、Θ、Ι、Κ、Λ、Μ、Ν、Ξ、Ο、Π、Ρ、Σ、Τ、Υ、Φ、Χ、Ψ、Ω、α、β、γ、δ、ε、ζ、η、θ、ι、κ、λ、μ、ν、ξ、ο、π、ρ、σ、τ、υ、φ、χ、ψ、ω
Α、Β、Γ、Δ、Ε、Ζ、Η、Θ、Ι、Κ、Λ、Μ、Ν、Ξ、Ο、Π、Ρ、Σ、Τ、Υ、Φ、Χ、Ψ、Ω、α、β、γ、δ、ε、ζ、η、θ、ι、κ、λ、μ、ν、ξ、ο、π、ρ、σ、τ、υ、φ、χ、ψ、ω
*2 选择<OCR(欧洲语言)>时,可以识别Arial类型、Times New Roman类型和Courier New类型字体。
检查原稿文档的格式
当创建可检索的PDF/XPS/OOXML文件时,使用适合OCR处理的原稿以改进处理准确性。
项目 | 详细说明 |
原稿格式 | 打印的文档、字处理器文档(包含文本、图形、照片、表格和无斜体字符的文档) |
文本格式 | 横向书写和纵向书写(也可以识别包含横向书写和纵向书写的文档) 欧洲语言和韩语文本仅可以识别横向书写。 无复杂纵列设置的1到3列文档 |
字符大小 | 8到40磅 |
表格格式(仅用于Word格式) | 符合以下条件的表格: 使用实线分隔的方形表格 最多含32列的表格 最多含32行的表格 |
|
适合OCR处理的某些原稿可能无法正确处理。每页包含大量文本的原稿可能无法实现高准确度。 由于原稿的背景颜色、字符格式和大小或斜体字符,字符可能会被替换为非预期的字符或丢失。* 可能无法复制段落符号、换行符或表格。* 插图、照片或印鉴的某些部分可能会被识别并替换为字符。* * 在Word选择为文件格式时。 |