
OCRで文字認識して読み込む
| OCR(文字認識)は、テキストとして認識可能な部分からテキストデータの抽出を行い、テキスト検索可能なPDF/XPS/OOXMLを作成する機能です。また、<高圧縮>を同時に指定することもできます。 この機能を使用するために必要なオプションおよびファイル形式については、システムオプションについてを参照してください。 |
OCRで読み込む
1
原稿をセットする 原稿をセットする
2
<スキャンして送信>を押す <メインメニュー>画面
3
スキャンの基本画面で宛先を指定する スキャンの基本画面について
4
必要に応じて読み込み設定をする スキャンの基本操作
5
ファイル形式を選択
複数ページの原稿をページごとに分割して、別々のファイルとして送信するときは、<ページごとに分割>を押して分割するページ数を入力  <OK>を押してください。1つのファイルとして読み込むときは<ページごとに分割> <設定取消>を押します。
<OK>を押してください。1つのファイルとして読み込むときは<ページごとに分割> <設定取消>を押します。
 PDFを選択する
PDFを選択する
1 | <PDF>を選択 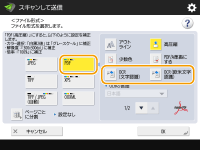 <OCR (欧米文字認識)>と<アウトライン>または<少数色>を選択した場合、OCR (欧米文字認識)を行うことができません。 <OCR (欧米文字認識)>と<高圧縮>を組み合わせた場合、<高圧縮/少数色時の画質レベル>の設定は無効になります。<高圧縮/少数色時の画質レベル> <OCR (欧米文字認識)>と<高圧縮>を組み合わせてPDFを作成した場合、<OCR(文字認識)>と<高圧縮>で作成したPDFに比べ、画質が異なる場合があります。 |

OCRで使用する言語を変更する場合は、<OCRの言語>を押して言語を選択 <OK>を押してください。
<OCR (欧米文字認識)>の認識言語は欧米言語のみです。OCR処理の基準となる設定や言語について
XPSを選択する
1 | <XPS>を選択 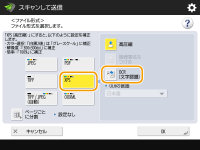 |
OCRで使用する言語を変更する場合は、<OCRの言語>を押して言語を選択 <OK>を押してください。
OOXMLでWord形式を選択する
1 | <OOXML>を選択 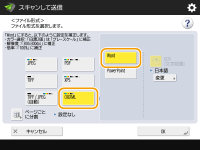 |
OCRで使用する言語を変更する場合は、<変更>を押して言語を選択 <OK>を押してください。
読み込む原稿に使用されている言語にあわせて、一言語または一グループを選択します。OCRで読み込む
OOXMLでPowerPoint形式を選択する
1 | <OOXML>を選択 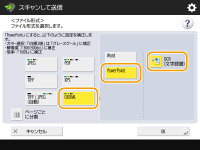 |
2 | OCRで使用する言語を選択 |
6
<OK>を押す
 |
原稿サイズが長尺原稿(432mm以上)のとき、<OCR(文字認識)>で送信することはできません。 |
|
<OCR(文字認識)設定>の<原稿向き自動検知>が<ON>のとき、ファイル形式で<PDF(OCR)>、<XPS(OCR)>または<OOXML(OCR)>を選択すると、原稿の向きを検知して自動的に回転して送信されます。<OCR (文字認識) 設定> <OCR(文字認識)>を選択すると、倍率は<等倍 (100%)>または<自動>でのみ送信できます。 <PDF>または<XPS>を選択した場合、<高圧縮>と<OCR(文字認識)>と組み合わせて設定できます。送信画面では<PDF(高圧縮)>または<XPS(高圧縮)>と表示されます。 <OOXML>から<Word>を選択した場合、読み込んだ背景画像を消去できます。不必要な画像が消えるため、Wordファイルの編集がしやすくなります。<Wordファイルに背景画像を含める> <スキャンして保存>機能を使用しているときは、<OOXML>の<Word>または<PDF>の<OCR (欧米文字認識)>を選択している時のみ、OCRの言語を指定できます。 |
文字が正しくOCR処理されない
テキスト検索可能なPDF/XPS/OOXMLを作成する際に、正常にOCR(光学式文字認識)処理が行われないことがあります。その原因として、本体の設定や原稿に使用している言語、文字種、原稿の形式などが、OCR処理の適性に合っていない場合があります。
本体の設定や対応言語を確認する
文字認識に関わる本体の設定を原稿に合わせて変更したり、本体が認識できる文字種や書体を原稿に使用したりすることで、正しくOCR処理されるようになります。
OCR処理の基準となる設定や言語について
項目 | 詳細 |
文字認識の基準となる言語の設定 | <ファイル形式>でOCR選択時に言語指定がある場合: 各ファイル形式で選んだ言語が、文字認識の基準になります。 |
認識できるアジア言語 *2 | 日本語、中国語(簡体字)、中国語(繁体字)、韓国語 認識できる文字種と書体について(アジア言語) |
認識できる欧文言語および言語グループ | 言語: 英語、フランス語、イタリア語、ドイツ語、スペイン語、オランダ語、ポルトガル語、アルバニア語、カタロニア語、デンマーク語、フィンランド語、アイスランド語、ノルウェー語、スウェーデン語、クロアチア語、チェコ語、ハンガリー語、ポーランド語、スロバキア語、エストニア語、ラトビア語、リトアニア語、ロシア語、ギリシャ語、トルコ語、スロベニア語*3、ルーマニア語*3、ブルガリア語*3、ヘブライ語*3 |
*1 リストに表示される言語は、異なる場合があります。また、英語、フランス語、イタリア語、ドイツ語、スペイン語、タイ語、ベトナム語のいずれかを選択した場合は、欧文言語の西ヨーロッパ言語(ISO)として認識されます。
*2 <OCR (欧米文字認識)>を選択した場合、アジア言語の認識は非対応となります。
*3 <OCR (欧米文字認識)>でのみ選択可能です。
*4 英語、フランス語、イタリア語、ドイツ語、スペイン語、オランダ語、ポルトガル語、アルバニア語、カタロニア語、デンマーク語、フィンランド語、アイスランド語、ノルウェー語、スウェーデン語が含まれます。
*5 クロアチア語、チェコ語、ハンガリー語、ポーランド語、スロバキア語が含まれます。
*6 エストニア語、ラトビア語、リトアニア語が含まれます。
認識できる文字種と書体について(アジア言語)
項目 | 詳細 |
認識できる文字種 | 日本語: アルファベット、数字、ひらがな、カタカナ、漢字(JIS 第一水準、JIS 第二水準(一部))、記号 中国語(簡体字): アルファベット、数字、漢字、記号 (GB2312-80) 中国語(繁体字): アルファベット、数字、漢字、記号 (Big5) 韓国語: アルファベット、数字、漢字、ハングル、記号 (KSC5601) |
認識できる書体 | マルチフォント対応(明朝体推奨) 斜体で書かれた文字は認識しない |
変換後の書体(ファイル形式にWord を選択した場合のみ) | 日本語: アジア系文字:MS 明朝 欧文文字:Century 中国語(簡体字): アジア系文字:SimSun 欧文系文字:Calibri 中国語(繁体字): アジア系文字:PMingLiU 欧文系文字:Calibri |
認識できる文字種と書体について(欧州言語)
項目 | 詳細 |
認識できる文字種 | アルファベット、認識言語の固有文字*1、数字、記号 |
認識できる書体 | マルチフォント対応(Times、Century、Arial推奨)*2 斜体で書かれた文字を認識する |
変換後の書体(ファイル形式にWord を選択した場合のみ) | Calibriで表示される 斜体は再現されない |
*1 ギリシャ語の場合、次の言語固有文字を認識できます。その他の言語は、各言語の固有文字を認識できます。ただし、言語によっては一部認識できない固有文字があります。
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ,υ, φ, χ, ψ, ω
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ,υ, φ, χ, ψ, ω
*2 <OCR (欧米文字認識)>を選択した場合、Arial系、Times New Roman系、Courier New系のフォントを認識します。
原稿の形式を確認する
テキスト検索可能なPDF/XPS/OOXMLを作成するときに、OCR処理に適した原稿を使用することで、処理結果の精度を上げることができます。
項目 | 詳細 |
原稿の形式 | 印刷文書、ワープロ文書(テキストや図、写真、表によって構成され、傾きのないもの) |
テキストの形式 | 横書き、縦書き(横書きと縦書きが混在した文書も認識可能) 欧文と韓国語は横書きのみ認識可能 1~3段組で複雑な入り組みのないもの |
文字サイズ | 8~40ポイント |
表の形式(Wordのみ対応) | 次の条件を満たす表 実線の罫線で構成された四角形 列数が32列以下 行数が32行以下 |
|
OCR処理に適した原稿でも、正しくOCR処理されない場合があります。1ページあたりの文字数が多い原稿は、処理結果の精度が上がらないことがあります。 地色や字体、文字の大きさ、文字の傾きなどによっては、意図しない文字に置き換えられたり、文字が欠落したりすることがあります。* 段落や改行、表が再現されないことがあります。* 図や写真、印鑑などの画像の一部が文字として認識され、文字に置き換えられることがあります。* *ファイル形式でWordを選択した場合 |