条形码的用法和格式
本节介绍支持的条形码类型及其用法和格式。
一维条形码
UPC-A
UPC-A条形码是美国用于向公众销售的产品的标准条形码格式。UPC-A仅包含数字数据,并编码12位数字。第一位是系统编号字符,随后的五位表示供应商识别码,再后五位表示产品编号,最后一位表示所需的检查和字符。由于“条形码打印”功能会自动计算检查和数字,因此不需要指定检查和数字。

每一位由两个线条和两个空白表示,其宽度计算为七个细线条。
系统编号字符以可读文本形式打印在条形码左侧,检查和数字以可读文本形式打印在条形码的最右侧。
系统编号可以是以下值:
0或7: | 常规UPC码 |
2: | 随机加权项 |
3: | 国家药品代码和国民健康相关产品代码 |
4: | 无代码格式限制时使用,带有非食用产品检查和数字 |
5: | 用于优惠券 |
1、6、8和9: | 保留 |
UPC-E (UPC-E0和UPC-E1)
UPC-E条形码非常适合用于小包装,因为其数据是压缩的。UPC-E条形码包含的信息与UPC-A条形码基本相同,只是UPC-E中至少含有四个抑制的零。条形码中的数字位数从12缩减为6。“条形码打印”功能接受“零抑制”版本的压缩和未压缩的UPC-E数据。如果发送的数据未压缩,“条形码打印”功能会自动压缩数据。
每一位由两个线条和两个空白表示,其宽度计算为七个细线条。请注意,可以激活条形码下方的标题文本以确认检查和计算。

EAN-8
EAN-8条形码在欧洲用于向公众销售的产品。EAN-8仅包含数字数据,并编码8位数字。前两位表示国家代码,随后的五位表示产品代码,最后一位表示所需的检查和字符。由于“条形码打印”功能会自动计算检查和数字,因此不需要指定检查和数字。
每一位由两个线条和两个空白表示,其宽度计算为七个细线条。

EAN-13
EAN-13条形码是在欧洲用于向公众销售的产品的标准条形码格式。EAN-13仅包含数字数据,并编码13位数字。前两位表示国家代码,随后的六位表示供应商识别码,再后四位表示产品代码,最后一位表示所需的检查和字符。(检查和字符与条形码的其余部分分离。这种分离在不同国家之间有所区别。)由于“条形码打印”功能会自动计算检查和数字,因此不需要指定检查和数字。如果检查和作为第13位发送,则会被忽略并重新计算。
所有EAN和UPC条形码都可以后随两位或五位数字来表示补充信息。

每一位由两个线条和两个空白表示,其宽度计算为七个细线条。
系统编号字符以可读文本形式打印在条形码左侧,检查和数字以可读文本形式打印在条形码的右侧。
Code 39
Code 39的实际名称是“3 of 9 bar code”。由于不仅编码数字,还编码大写字母和标点,因此Code 39可能是最常用的条形码。空白编码为线条。在“条形码打印”功能自动生成的开始和停止字符“*”之间编码文本。
条形码打印功能包含“3 of 9 bar code”的三种变体:有起始空白和无起始空白。字样24670和24671在创建条形码时不会将起始空白编码到数据中;但是,字样24672和24673会编码起始空白。字样10001具有固定的条宽/空宽,仅高度可定义,单位为半点。
以下是字样10001的调用顺序:<Esc>(10Q<Esc>(sp<height>v

Danish Postal 39条形码(仅用于丹麦)
这是在丹麦用于邮政装运的包裹标签的一种特殊3 of 9条形码。Danish Postal 39条形码包含10位数字、1个特殊检查和,并以“DK”结尾。

French Postal 39条形码(仅用于法国)
这是在法国用于挂号信件格式(“Recommandés”)的一种特殊3 of 9条形码。French Postal 39条形码以“RA”或“RB”开头,然后包含8位数字、1个特殊检查和,并以“FR”结尾。

Extended 39
Extended 39条形码基于标准3 of 9条形码,但可通过对要编码字符串中的每个字符生成两个字符编码所有ASCII字符。Extended 39条形码支持从0到126的所有ASCII码,并且条形码图案相当大。
Interleaved 2 of 5
也称为“25 Interleaved”。Interleaved 2 of 5条形码仅包含数字数据,并且要求要编码的字符串具有偶数位数。位数可以为2到30。

Industrial和Matrix 2 of 5
Industrial 2 of 5和Matrix 2 of 5条形码仅包含数字数据,并且可以具有1到30位。

Code 128
大多数条形码标签的新标准。Code 128是用于数字和字母数字字符串的紧凑式条形码。它有三个模式:A、B或C,分别编码范围不同的字符。Code 128 Auto是“条形码打印”功能独有的功能。利用这种功能无需分析要编码的字符串即可编码所有128个ASCII字符,并可自动确定所需使用的Code 128模式。
“条形码打印”功能分析数据并在A、B和C模式之间动态切换以提供最紧凑的代码。Code 128 Auto完全符合在同一图案内使用Code 128模式B和C的托盘标签新全球标准。

EAN-128和UCC-128
EAN-128和UCC-128是以FNC 1码开头且长度可变的条形码,基于编码字符串的Code 128 A、B和C模式。EAN-128用于托盘标签和EDI(电子数据交换)相关的条形码标签。“条形码打印”功能自动在条形码的开头添加FNC 1码,并在结尾添加检查和。

German 25 Postal条形码(仅用于德国)
German 25 Postal条形码是在德国用于邮政装运的包裹标签的一种特殊25 Interleaved码。用于这些标签的两种代码为:
Leitcode,用于编码目标地址区域,需要13位。
Identcode,用于编码跟踪编号,需要11位。

Codabar/Monarch
编码数字和标点字符。多用于血液产品的标签。

Code 93
Code 39的压缩版本。

Extended Code 93
Extended Code 39的压缩版本。

MSI Plessey
MSI Plessey条形码仅包含数字数据,用于杂货行业的标签。

ZIP + 4 Postnet (仅用于美国)
将邮政编码打印为条形码加速通过美国邮政邮寄的邮件。
USPS智能邮件条形码(仅限于美国)
从2007年起,寻求更大邮件折扣的美国公司在2009年秋天强制推行USPS智能邮件条形码。
数据语法:
条形码标识(2位数)、特殊服务(3位数)、邮寄者标识(6位数)、序号(9位数0、交割点邮编(0、5、9 或11位数)
示例:05,987,978425,684745129,92130
可以激活条码下方或上方的标题文本,文字根据USPS规范自动格式化。
USPS Tray条形码(仅用于美国)
自1997年起,自动发送优先投递的邮件、期刊、普通和强化的邮政载体线路标准信件尺寸邮件,以及优先投递的扁平尺寸邮件,要求使用带有特殊25 Interleaved条形码的条形码托盘标签。

USPS Zebra条形码(仅用于美国)
美国邮政管理局定义了Zebra码。这是条形码右侧的一系列对角线,仅用作托盘内包含带条形码邮件的可见指示。无条形码邮件的托盘标签上不能出现该码。
此标准开始于1997年7月。由于其简单性,Zebra码在“条形码打印”功能中作为只有一个使用斜线字符“/”(ASCII值47)的对角粗条形码线条的字体来执行。
要创建USPS Zebra条形码,必须调用该字体并将3个连续无空格的斜线字符发送到PCL转义码序列中。
示例:<Esc>(10U<Esc>(s0p2.50h29vsb23591T///
USPS Sack条形码(仅用于美国)
自1997年7月1日生效起,自动发送袋装期刊类邮件和标准扁平尺寸邮件要求使用带有特殊25 Interleaved条形码的条形码邮袋标签。

Singapore 4 State条形码
新加坡邮政管理局正在推动使用4 State条形码以加快邮件分拣。这种4 State条形码编码6位数字,并具有附加于数据的检查和。必须将这六位数字输入“条形码打印”功能中,以便该功能自动计算并打印检查和。
请注意,Singapore 4 State条形码必须以常规文本字体转义序列结尾。
Netherlands KIX条形码
荷兰邮政管理局正在推动使用4 State条形码以加快邮件分拣。这种4 State条形码编码5到12字符的字符串,并具有附加于数据的检查和。必须将有效的字符串输入到“条形码打印”功能中。
请注意,Netherlands KIX条形码必须以常规文本字体转义序列结尾。
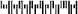
UK Royal Mail 4 State Customer条形码
英国邮政管理局正在推动使用4 State条形码以加快邮件分拣。这种4 State条形码编码可变位数的数字和字母,并具有附加于数据的检查和。必须将正确的数字和字母输入“条形码打印”功能中,以便该功能自动计算并打印检查和。
请注意,UK Royal Mail 4 State Customer条形码必须以常规文本字体转义序列结尾。
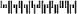
Australia Post 4 State条形码
Australia Post 4 State条形码制定于1998年,由此澳大利亚邮政管理局可以通过从信件读取的条形码分拣收到的邮件。有三种不同类型的条形码,对应于FCC(格式控制码)值11、59和62。“条形码打印”功能只需要DPID(递送点标识符)和客户信息即可自动生成FCC或Reed-Solomon检查和。
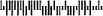
对于各类型的条形码,必须以特定格式发送数据:
仅含有分拣码(DPID)的标准Customer Bar Code(37-CUST):
<DPID>
Customer Bar Code 2(52-FF-MET)、DPID和16线条的客户信息(长度可以为8位数字或5位字母数字字符):
<DPID>、<CustomerInfo>
Customer Bar Code 3(67-FF-MET)、DPID和31线条的客户信息(长度可以为15位数字或10位字母数字字符):
<DPID>、<CustomerInfo>
示例:<Esc>(s1p24787T12345678,7V 5<Esc>(s0p12h10v4099T
 |
<DPID>是分拣编码,长度必须为8位。<CustomerInfo>是客户信息,p参数选择N或C符号集,其中N =数字数据,C = 字母数字数据。 |
 |
有关在Australia Post 4 State条形码中使用p参数转义码的信息,请参阅“字体参数”。 |
二维条形码
|
要编码包含转义字符(十进制27或十六进制1B)的数据,必须将数据纳入在“透明打印数据”模式序列中。(请参阅“打印条形码”) |
UPS MaxiCode
MaxiCode条形码是由884个围绕一个同心圆定位图案的六边形构成的二维条形码。每一位信息由一个六边形编码。一平方英寸(此类条形码的近似固定尺寸)最多可以编码100个字符的信息。MaxiCode符号包括内置纠错能力、自动数据压缩和完整的ASCII字符集。
MaxiCode作为一种多用途EDI(电子数据交换)二维条形码,由UPS(联合包裹服务公司)创造,并得到AIM(自动识别制造商)认可(由AIM正式指定为“Uniform Symbology Specification MaxiCode”)。UPS使用MaxiCode编码所有包裹信息以便为客户提供更快、更好的服务。

MaxiCode数据是由标题、ANSI(美国国家标准学会)信息和“传输终止符”代码构成的字符串。
以下是UPS MaxiCode的ANSI信息中的详细信息。
|
请始终为MaxiCode数据使用大写字符。 |
MaxiCode信息字段列表
字段名称 | 说明 | 需要/可选 |
目的地邮政编码 | 5或9个字母数字字符 | 需要 |
目的地国家代码 | 3位数 | 需要 |
服务类 | 3位数 | 需要 |
跟踪编号 | 10或11个字母数字字符 | 需要 |
承运人标准字母编码 | UPSN | 需要 |
托运人编号 | 6个字母数字字符 | 需要 |
接运日 | 3位数 | 需要 |
装运识别码 | 1到30个字母数字字符 | 可选 |
物品x个/总数n个 | x=1至3位数 n=1至3位数 示例:20/458 | 需要 |
重量(g) | 1到3位数 | 需要 |
地址验证(是/否) | 是或否 | 需要 |
目的地地址 | 1到35个字母数字字符 | 可选 |
目的地城市 | 1到20个字母数字字符 | 需要 |
目的地州 | 两个大写字母 | 需要 |
不同字段由<Gs>(群分隔符;ASCII 29、十六进制1D)分隔。条形码数据以<Eot>(传输终止符;ASCII 04、十六进制04)结尾。要分隔格式类型,请使用<Rs>(字段分隔符;ASCII 30、十六进制1E)。
要分隔主要和次要地址编码,请使用<Fs>(地址字段分隔符;ASCII 28、十六进制1C)。“条形码打印”功能预期将从应用程序同时获得主要和次要信息,以逗号分隔。
主要信息包含以下信息:
1. 标签编号 |
2. 装运的标签数量 |
3. MaxiCode模式。美国国内运输使用模式2,国际运输使用模式3 |
4. 邮政编码 |
5. 国家代码 |
6. 服务类 |
|
所有参数之间必须使用逗号分隔。 |
次要信息包含以下信息:
示例 | |
1. ANSI信息标题 | [ )><Rs> |
2. 运输数据格式标题 | 01<Gs>96 |
3. 跟踪编号 | 1Z00004951<Gs> |
4. SCAC(承运人标准字母编码) | USPN<Gs> |
5. UPS托运人编号 | 06X610<Gs> |
6. 接运日 | 159<Gs> |
7. 装运识别码 # | 1234567<Gs> |
8. 包裹n/x | 1/1<Gs>* |
9. 包裹重量 | 10<Gs> |
10. 地址验证 | Y<Gs> |
11. 运输目标地址 | 634 ALPHA DR<Gs> |
12. 运输目标城市 | PITTSBURGH<Gs> |
13. 运输目标州 | PA |
14. 格式终止符 | <Rs> ASCII 30 |
15. 传输终止符 | <Gs> ASCII 04 |
* 主要信息中也包含此信息。
|
UPS MaxiCode预期次要信息中填写总计84个填充字符。“条形码打印”功能自动将此数据填写到MaxiCode的右侧。(填充字符是“!”,ASCII 33、HEX 21。) 次要信息不能长于84个字符。因此,如果次要信息的总长度大于84个字符,则必须缩减目的地地址的长度。在MaxiCode数据中,目的地地址是可选的。如果MaxiCode数据过长,“条形码打印”功能将不会打印MaxiCode,而是会打印一条错误信息,说明比最大长度84超出多少个字符。 空白字段也必须包括<Gs>分隔符。 |
在<Eot>字符之后,应用程序必须立即发送PCL转义序列以切换为除MaxiCode以外的字体。
以下是从MaxiCode切换为Courier font 10CPI的转义序列:
<Esc>(s0p10h12vbs4099T
|
如果使用除PC-8以外的字符集,应在选择新字体之前重新发送字符集选择。 |
示例:
<Esc>(s24800T1,1,2,152382802,840,001,[)><RS>01<GS>96995011234<GS>840<GS>025<GS>1Z07000168<GS>UPSN<GS>WX9031<GS>272<GS><GS>1/1<GS>15<GS>Y<GS>123<FS>300<GS><GS>AK<RS><EOT><Esc>(s0p10h12vbs4099T
PDF-417
PDF-417条形码是由Symbol Technology创造的高密度二维条形码,是美国ANSI/AIM标准。此条形码由按列排列的黑色小矩形行堆叠而成。行数和列数可由用户定义或自动设置为适合某个比率(2:3是最常用的比率)。
PDF-417包括内置纠错能力、自动数据压缩及完整的ASCII和二进制字符集。基于实现的压缩级别,每个PDF-417条形码最多可以编码1,848个字符。
PDF-417支持两种编码模式:ASCII(字母、标点和数字)和二进制(0和244之间的任何二进制值)。ASCII模式的数据密度优于二进制模式(每cm2最多106与177字节),并且可以编码更多的数据(最多1,848字节与1,108字节)。“条形码打印”功能为提供的数据自动选择最佳编码模式(二进制或ASCII)。
PDF-417条形码使用激光扫描器和CCD(电荷耦合器件)相机读取。
行数(最小值/最大值):3/90
列数(最小值/最大值):1/30
PDF-417条形码有许多使用PCL转义序列的p参数激活的符号选项。
|
行数与列数的乘积必须小于929。 有关在PDF-417条形码中使用p参数转义码的详细信息,请参阅“字体参数”。 |
Data Matrix
Data Matrix是由RVSI-Acuity CiMatrix研制的高密度二维矩阵条形码符号,可以在很小的空间中编码大量信息。Data Matrix符号具有使用ECC200错误检查方法的广泛纠错能力。Data Matrix符号可以存储1至3,116个数字或2,335个字母数字字符,大小可在1平方毫米至14平方英寸之间缩放。
由于Data Matrix符号的整体尺寸可无限扩展,因此,只要尺寸和读取设备组合正确,几乎可以在任何距离读取Data Matrix符号。
“条形码打印”功能可以通过定义黑色小方块的高度和宽度来缩放Data Matrix条形码。此条形码还可以通过分析数据自动优化编码(二进制、文本和数字)。

|
有关Data Matrix符号选项的详细信息,请参阅“字体参数”。 |
Aztec Code
Aztec Code是由Welch Allyn研制的二维矩阵条形码符号。按照设计,此条形码结合几种第一代符号的最佳特性,并特别注重易打印性、方向、字段变形、使用用户选择的冗余的高级数据安全及对从小到大的数据信息的高效存储。最小的Aztec Code符号编码13个数字或12个字母,而最大的Aztec Code符号编码3,832个数字、3,067个字母或1,914字节的二进制数据。“条形码打印”功能可以通过定义黑色小方块的高度和宽度来缩放Aztec Code。

|
有关Aztec Code符号选项的详细信息,请参阅“字体参数”。 |
Codablock F
Codablock F是由ELMICRON作为对Code 128的扩展而研制的一种二维条形码。使用Codablock F,可以将Code 128分隔为几部分,并将它们排列在一个多行符号中。Codablock F符号可以包含2到44行字符且最多每行61个字符(对于数字数据,每行最多122个),并支持Code 128的大多数功能。

|
有关Codablock F符号选项的详细信息,请参阅“字体参数”。 |
QRCode
QRCode是由DENSO Corporation研制的二维矩阵条形码符号。有两种模式可用:“Model 1”和“Model 2” (“Model 1”的高级版本)。“条形码打印”功能支持四种级别的错误纠正、大范围的符号尺寸,并可以通过定义黑色小方块的高度和宽度缩放QRCode。
QRCode符号可以包括高压缩的数字和字母数字数据、二进制、日语假名和日语汉字数据。每个QRCode符号的最大字符数如下所示:
QRCode | 型号 1 | 型号 2 |
数字字符 | 1,167 | 7,089 |
字母数字字符 | 707 | 4,296 |
字节 | 486 | 2,953 |
日语汉字字符 | 299 | 1,817 |

瑞士QR代码
瑞士QR代码是改进型QR代码符号,符合非常严格的要求,可以在瑞士的银行发起付款,其中间标有瑞士十字。它会自动缩放以适应预期的文档表面,并在其中心处带有瑞士十字。瑞士QR代码无需定义任何参数,只需调用字体序列然后发送数据,其中字段使用回车符分隔,然后在数据末尾调用新字体至条形码。

|
条形码四周必须留出5 mm的白边,以确保没有线条、文字或图形接近条形码。 |
OMR标记
OMR标记是打印的邮件表单上的横向或纵向的黑色实线。邮件处理设备检查输入其中的每页上的这些线条。对这些标记的跟踪会触发机械操作,如折叠应一起插入信封的的所有页。
“条形码打印”功能可以生成由收发室中的插入、折叠或密封系统使用的OMR标记。
OMR标记没有标准。不同机器之间及每种OMR扫描软件之间的规格有所不同。但是,可以配置“条形码打印”功能处理任一规格。
可以使用b、s和v参数定义OMR标记的宽度、间隔和长度。
|
一些邮件处理设备使用较粗的标记指示开始和停止位置,而其他设备对于所有操作仅使用一种类型的标记。 数据中的标记是从上至下定义的。 |
用法:仅有3种字符可以用于OMR标记数据。“0”、“1”和“2”。
0:此标记被跳过。 |
1:普通标记。(粗细度由第一个b参数定义。) |
2:粗标记。(粗细度由第二个b参数定义。) |
欧元货币符号和附加字体
“条形码打印”功能具有可以与标签和其他文档上的条形码一起使用的字体和可缩放的徽标、欧元符号、制造、电子和安全符号。
欧元和其他货币符号
转义序列:<Esc>(10Q<Esc>(s1p<size>vsb10452T
<size>是以磅(1/72")为单位的符号尺寸。

支持传统条形码命令
这些条形码具有固定的条宽/空宽,只能定义尺寸参数。
39码,无可读文本,条宽比1:3
转义序列:<Esc>(10Q<Esc>(s1p<size>vsb10000T
转义序列:<Esc>(10Q<Esc>(s1p<size>vsb10001T
39码,可读文本,条宽比1:3
转义序列:<Esc>(10Q<Esc>(s1p<size>vsb10004T
39码,无可读文本,条宽比1:2.5
转义序列:<Esc>(10Q<Esc>(s1p<size>vsb10006T
39码,可读文本,条宽比1:2.5
转义序列:<Esc>(10Q<Esc>(s1p<size>vsb10007T
39码,无可读文本,条宽比1:2.5
转义序列:<Esc>(10Q<Esc>(s1p<size>vsb10003T
39码,可读文本,条宽比1:2.5
转义序列:<Esc>(10Q<Esc>(s1p<size>vsb10005T
|
这些传统条形码将空白编码为字符“@”。 |
制造和安全符号
转义序列:<Esc>(10Q<Esc>(s1p<size>vsb10400T
<size>是以磅(1/72")为单位的符号尺寸。
特殊多字符符号
Green Point符号:<Esc>)10Q<Esc>)s1p20vsb10400TE
含文本:<Esc>)10Q<Esc>)s1p20vsb10400TDE
含灰色箭头:<Esc>)10Q<Esc>)s1p20vsb10400Td
<Esc>*c15G<Esc>*v2Te <Esc>*vT
回收标志:<Esc>(10Q<Esc>(s1p20vsb10400Tghij<8>123
电子和安全符号
转义序列:<Esc>(10Q<Esc>(s1p<size>vs3b10400T
<size>是以磅(1/72")为单位的符号尺寸。

Odette运输标签宏
“条形码打印”功能包含汽车行业使用的VDA 4902/Odette标签。此标签以从使用PCL5宏编号的任何应用程序中均可检索到的PCL5宏的形式置入。
如果要使用Macro TTF字体:
安装Macro Exec TTF字体,然后使用这种字体输入宏编号。
如果要使用PCL5命令:
要在页面上打印一个空标签,请在页面开头发送以下序列:
~&l1E~&a0h0V~&fs###y3x1S
要在页面上打印两个空标签,请在页面开头发送以下序列:
~&l1E~&a0h0V~&fs###y3x1S~&a0h4100V~&fs###y3x1S
|
必须使用三位宏编号替代###(请参阅下表)。 '上面的PCL转义序列中的~是FreeScape字符。如果已经从<Esc>**#J转义序列或从FreeScape菜单将其更换为其他值,请将其替换为新值。 |
V3德语 | V3英语 | V3法语 | V3意大利语 | V3西班牙语 | V4英语 | V4德语 |
300 | 301 | 302 | 303 | 304 | 311 | 312 |
添加了数据、条形码和安全符号的Odette标签宏的示例。

|
安全符号包括在安全符号字体中。 |