Scannen met de OCR-functie

|
Met deze modus kunt u OCR (optical character recognition) uitvoeren om bij de scan gegevens te extraheren die herkenbaar zijn als tekst, en een PDF-, XPS- of OOXML-bestand (pptx, docx) te maken dat doorzoekbaar is. U kunt ook <Compact> instellen als u PDF of XPS als bestandsindeling selecteert.
Voor informatie over de optionele producten die vereist zijn om deze functie te gebruiken en de bestandsindelingen, raadpleegt u Systeemopties.
|
Scannen met OCR
1
Plaats het origineel. Originelen plaatsen
2
Druk op <Scannen en verzenden>. Het scherm <Home>
3
Geef de bestemming op het scherm met basisfuncties voor scannen op. Scherm met basisfuncties voor scannen
4
Wijzig desgewenst de scaninstellingen. Basisbewerkingen voor het scannen van originelen
5
Selecteer een bestandsindeling.
Indien u meerdere afbeeldingen wilt scheiden en deze wilt verzenden als afzonderlijke bestanden die elk uit slechts één pagina bestaan, drukt u op <Verdeel in pagina's>  geef het aantal te splitsen pagina's op met druk op <OK>. Als u de afbeeldingen als één bestand wilt scannen, drukt u op <Verdeel in pagina's> <Annuleer inst.>.
geef het aantal te splitsen pagina's op met druk op <OK>. Als u de afbeeldingen als één bestand wilt scannen, drukt u op <Verdeel in pagina's> <Annuleer inst.>.
 PDF selecteren
PDF selecteren
|
1
|
Selecteer <PDF>
/b_D22500_C.gif)

OCR (Precisie-prioriteit) kan niet worden uitgevoerd als <Overtrekken & Gladmaken> is geselecteerd met <OCR (Precisie-prioriteit)>.
Als u zowel <OCR (Precisie-prioriteit)> als <Compact> selecteert, wordt de instelling <Beeldkwaliteitsniveau voor Compact> uitgeschakeld. <Beeldkwaliteitsniveau voor Compact>
Als u een PDF-bestand maakt met zowel <OCR (Precisie-prioriteit)> als <Compact> ingesteld, kan de beeldkwaliteit verschillen van een PDF-bestand dat is gemaakt met <OCR (Snelheids-prioriteit)> en <Compact> ingesteld.
Als u een taal wilt wijzigen om voor OCR te gebruiken: druk op <OCR-taal>
Alleen Europese talen kunnen worden gedetecteerd met <OCR (Precisie-prioriteit)>. Instellingen en talen voor verwerking met OCR
|
XPS selecteren
|
1
|
Selecteer <XPS>
/b_D02128_C.gif)

Als u een taal wilt wijzigen om voor OCR te gebruiken: druk op <OCR-taal>
|
De Word-indeling selecteren voor OOXML
|
1
|
Selecteer <OOXML>
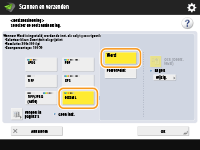

Als u een taal wilt wijzigen voor gebruik voor OCR, drukt u op <Wijzigen>
Selecteer een taal of een talengroep in overeenstemming met de taal die wordt gebruikt in de gescande documenten.
|
De PowerPoint-indeling selecteren voor OOXML
|
1
|
Selecteer <OOXML>
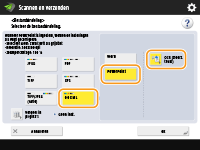
|
|
2
|
Selecteer een taal om voor OCR te gebruiken
|
6
Druk op <OK>.
|
|
|
Als u voor de bestandsindeling <PDF (OCR)>, <XPS (OCR)> of <OOXML (OCR)> selecteert en <Smart Scan> is ingesteld op <Aan> in <OCR (Text Searchable) Settings>/<OCR (Snelheids-prioriteit)>, wordt de oriëntatie van het origineel gedetecteerd en wordt het document zo nodig automatisch geroteerd voor verzending. <Instellingen OCR (Doorzoekbare tekst)>
Als u als bestandsindeling <PDF> of <XPS> selecteert, kunt u <Compact> en <OCR (Doorzoekbare tekst)> tegelijk instellen. In dat geval wordt <PDF (Compact)> of <XPS (Compact)> weergegeven als bestandsindeling op het scherm met basisfuncties voor scannen en verzenden.
Als u <Word> selecteert voor <OOXML>, kunt u instellen dat de gescande achtergrondafbeeldingen worden verwijderd. U kunt Word-bestanden genereren, die gemakkelijk te bewerken zijn, zonder ongewenste afbeeldingen. <Achtergrondafb. opnemen in Word-bestand>
Als u momenteel de functie <Scannen en opslaan> gebruikt, kunt u de OCR-taal alleen opgeven wanneer <Word> is geselecteerd voor <OOXML> of wanneer <OCR (Precisie-prioriteit)> is geselecteerd voor <PDF>.
|
OCR-resultaten zijn niet bevredigend
Wanneer u doorzoekbare PDF-/XPS-/OOXML-bestanden maakt, wordt OCR (Optical Character Recognition) misschien niet goed verwerkt. Dat kan zijn doordat de instellingen op de machine, of de taal, tekentype of indeling van het originele document niet geschikt zijn voor verwerking met OCR.
De machine-instellingen en ondersteunde talen controleren
U kunt de OCR-verwerking verbeteren door de machine-instellingen voor tekenherkenning aan te passen op basis van de originelen, of door geschikte tekentypes of lettertypes in de originelen te gebruiken, zodat de machine de tekens kan herkennen.
Instellingen en talen voor verwerking met OCR
|
Item
|
Details
|
|
Taalinstellingen voor tekenherkenning
|
Als een taal is opgegeven met OCR geselecteerd in <Bestandsindeling>:
Tekens worden herkend op basis van de taal die u selecteert voor elke bestandsindeling. Als een taal niet is opgegeven met OCR geselecteerd in <Bestandsindeling>:
Tekens worden herkend op basis van de taal die u selecteert in <Andere Taal/Toetsenbord> (<Andere Taal/Toetsenbord>).*1 |
|
Herkenbare Aziatische talen*2
|
Japans, Chinees (vereenvoudigd), Chinees (traditioneel), Koreaans
Herkenbare tekentypes en lettertypes (Aziatische talen) |
|
Herkenbare Europese talen en taalgroepen
|
Talen:
Engels, Frans, Italiaans, Duits, Spaans, Nederlands, Portugees, Albanees, Catalaans, Deens, Fins, IJslands, Noors, Zweeds, Kroatisch, Tsjechisch, Hongaars, Pools, Slovaaks, Ests, Lets, Litouws, Russisch, Grieks, Turks, Sloveens*3, Roemeens*3, Bulgaars*3, Hebreeuws*3 Taalgroepen:
West-Europees (ISO)*4, Centraal-Europees (ISO)*5, Baltisch (ISO)*6 Herkenbare tekentypes en lettertypes (Europese talen) |
*1 Weergegeven talen in de lijst kunnen afwijken. Als u Engels, Frans, Italiaans, Duits, Spaans, Thai of Vietnamees selecteert, wordt de geselecteerde taal herkend als West-Europees (ISO).
*2 Aziatische talen kunnen niet worden gedetecteerd als <OCR (Precisie-prioriteit)> is geselecteerd.
*3 Dit kan alleen worden geselecteerd met <OCR (Precisie-prioriteit)>.
*4 Inclusief Engels, Frans, Italiaans, Duits, Spaans, Nederlands, Portugees, Albanees, Catalaans, Deens, Fins, IJslands, Noors en Zweeds.
*5 Inclusief Kroatisch, Tsjechisch, Hongaars, Pools en Slovaaks.
*6 Inclusief Ests, Lets en Litouws.
Herkenbare tekentypes en lettertypes (Aziatische talen)
|
Item
|
Details
|
|
Herkenbare tekentypes
|
Japans:
alfanumerieke tekens, Kana-tekens, Kanji-tekens (JIS eerste niveau en een aantal van JIS tweede niveau), symbolen Chinees (vereenvoudigd):
alfanumerieke tekens, Chinese tekens, symbolen (GB2312-80) Chinees (traditioneel):
alfanumerieke tekens, Chinese tekens, symbolen (Big5) Koreaans:
alfanumerieke tekens, Chinese tekens, Hangul-tekens, symbolen (KSC5601) |
|
Herkenbare lettertypes
|
Meerdere lettertypes worden ondersteund. (Min-cho-type wordt aanbevolen.)
Gecursiveerde tekens worden niet herkend.
|
|
Lettertypes die worden gebruikt voor geconverteerde tekens (alleen als Word is geselecteerd als bestandsindeling)
|
Japans:
Aziatische tekens: MS Mincho Europese tekens: Century Chinees (vereenvoudigd):
Aziatische tekens: SimSun Europese tekens: Calibri Chinees (traditioneel):
Aziatische tekens: PMingLiU Europese tekens: Calibri |
Herkenbare tekentypes en lettertypes (Europese talen)
|
Item
|
Details
|
|
Herkenbare tekentypes
|
Alfanumerieke tekens, speciale tekens van de herkende taal*1, symbolen
|
|
Herkenbare lettertypes
|
Meerdere lettertypes worden ondersteund. (Times, Century en Arial worden aanbevolen.)*2
Gecursiveerde tekens worden herkend.
|
|
Lettertypes die worden gebruikt voor geconverteerde tekens (alleen als Word is geselecteerd als bestandsindeling)
|
Calibri
Cursief wordt niet overgenomen.
|
*1 De volgende speciale Griekse tekens worden herkend. Speciale tekens uit elke taal worden ook herkend. Sommige speciale tekens kunnen niet worden herkend, afhankelijk van de talen.
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ, υ, φ, χ, ψ, ω
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ, υ, φ, χ, ψ, ω
*2 Wanneer <OCR (Precisie-prioriteit)> is geselecteerd, worden de letterypen van het type Arial, Times New Roman en Courier New herkend.
De indeling van de originele documenten controleren
Gebruik originelen die geschikt zijn voor OCR-verwerking om de nauwkeurigheid te verbeteren bij het maken van doorzoekbare PDF-/XPS-/OOXML-bestanden.
|
Item
|
Details
|
|
Origineelindeling
|
Afgedrukte documenten, documenten van een tekstverwerker (documenten bestaand uit tekst, grafieken, foto's of tabellen, en zonder tekenhelling)
|
|
Tekstopmaak
|
Horizontale en verticale tekst (documenten met zowel horizontale als verticale tekst kunnen ook worden herkend)
Alleen horizontale tekst kan worden herkend voor Europese talen en Koreaanse tekst.
Documenten met een tot drie kolommen zonder complexe kolominstellingen
|
|
Tekengrootte
|
8- tot 40-punts
|
|
Tabelopmaak (alleen voor Word-indeling)
|
Tabellen die aan de volgende voorwaarden voldoen:
Tabellen bestaan uit vierkanten met ononderbroken lijnen
Tabellen met maximaal 32 kolommen
Tabellen met maximaal 32 rijen
|

|
Misschien worden bepaalde originelen die geschikt zijn voor OCR-verwerking, niet goed verwerkt.Misschien wordt er geen hoge graad van nauwkeurigheid bereikt bij originelen met een grote hoeveelheid tekst op elke pagina.
Misschien worden tekens vervangen door onbedoelde tekens, of ontbreken ze vanwege de achtergrondkleur van het origineel, de vorm en grootte van de tekens of hellende tekens.*
Alinea's, regeleindes of tabellen worden misschien niet overgenomen.*
Sommige delen van illustraties, foto's of zegelafdrukken worden misschien herkend als tekens en vervangen met tekens.*
*Wanneer Word is geselecteerd als bestandsindeling.
|