Skanowanie z wykorzystaniem funkcji optycznego rozpoznawania tekstu (OCR)

|
Tryb ten umożliwia poddanie zeskanowanego obrazu procesowi optycznego rozpoznawania znaków (OCR) w celu pozyskania danych, które można rozpoznać jako tekst w celu utworzenia przeszukiwalnego pliku PDF/XPS/OOXML (pptx/docx). Jeżeli jako format pliku wybrany zostanie PDF albo XPS, możesz również wybrać pozycję <Kompresja>.
Aby uzyskać więcej informacji na temat produktów opcjonalnych wymaganych do korzystania z tej funkcji i formatów plików, patrz Opcje systemu.
|
Skanowanie z wykorzystaniem technologii OCR
1
Umieść oryginał. Umieszczanie oryginałów
2
Naciśnij <Skanuj i wyślij>. Ekran <Główne Menu>
3
Określ odbiorcę na ekranie podstawowych funkcji skanowania. Ekran Podstawowych funkcji skanowania
4
Wybierz ustawienia skanowania według potrzeb. Podstawowe działania związane ze skanowaniem oryginałów
5
Wybierz format pliku.
Jeżeli chcesz rozdzielić wiele obrazów i wysłać je jako osobne pliki, z których każdy zawiera tylko jedną stronę, naciśnij przycisk <Podziel na Strony>  wprowadź liczbę stron do podziału naciśnij przycisk <OK>. Jeżeli chcesz zeskanować obrazy do pojedynczego pliku, naciśnij po kolei opcje <Podziel na Strony> <Anuluj Ustawienia>.
wprowadź liczbę stron do podziału naciśnij przycisk <OK>. Jeżeli chcesz zeskanować obrazy do pojedynczego pliku, naciśnij po kolei opcje <Podziel na Strony> <Anuluj Ustawienia>.
 Aby wybrać PDF
Aby wybrać PDF
|
1
|
Wybierz <PDF>
/b_D22500_C.gif)

OCR (Priorytet precyzji) cannot be performed if <Ograniczone kolory> lub <Śledzenie i wygładzanie> is selected with <OCR (Priorytet precyzji)>.
Jeśli ustawisz zarówno opcję <OCR (Priorytet precyzji)>, jak i <Kompresja>, ustawienie <Poz. jakości obrazu dla ogr. koloro./skompre.> jest wyłączone. <Poz. jakości obrazu dla ogr. koloro./skompre.>
W przypadku tworzenia pliku PDF z ustawioną zarówno opcją <OCR (Priorytet precyzji)>, jak i <Kompresja>, jakość obrazu może się różnić od pliku PDF utworzonego z ustawioną opcją <OCR (Priorytet precyzji)> i <Kompresja>.
Aby zmienić język używany na potrzeby OCR, naciśnij opcję <Język OCR>
Tylko języki europejskie można wykryć za pomocą opcji <OCR (Priorytet precyzji)>. Ustawienia i języki odpowiednie dla OCR
|
Aby wybrać XPS
|
1
|
Wybierz <XPS>
/b_D02128_C.gif)

Aby zmienić język używany na potrzeby OCR, naciśnij opcję <Język OCR>
|
Wybór formatu programu Word w standardzie OOXML
|
1
|
Wybierz po kolei opcje <OOXML>
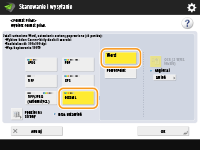

Aby zmienić język używany przez funkcję OCR, naciśnij przycisk <Zmień>
Wybierz język albo grupę języków zgodnie z językiem skanowanych dokumentów.
|
Wybór formatu programu PowerPoint w standardzie OOXML
|
1
|
Wybierz po kolei opcje <OOXML>
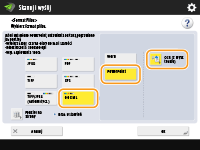
|
|
2
|
Wybierz język stosowany do funkcji OCR
|
6
Naciśnij <OK>.

|
|
Długie oryginały (powyżej 432 mm) nie mogą być stosowane w przypadku użycia funkcji <OCR (Z wysz. tekstu)>.
|
|
|
|
Gdy jako format pliku wybrana zostanie pozycja <PDF (OCR)>, <XPS (OCR)> albo <OOXML (OCR)>, a dla opcji <Inteligentne Skanowanie> zostanie wybrane ustawienie <Włącz> w <OCR (Text Searchable) Settings>/<OCR (Priorytet precyzji)>, zostaje wykryta orientacja tekstu, a dokument w razie potrzeby automatycznie obrócony jeszcze zanim zostanie wysłany. <Ustawienia OCR (z wyszukiwaniem tekstu)>
Jeżeli wybierzesz pozycję <OCR (Z wysz. tekstu)>, możesz wysyłać wyłącznie dokumenty z powiększeniem <1:1> albo <Auto>.
Jeżeli jako format pliku wybierzesz <PDF> albo <XPS>, możesz użyć opcji <Kompresja> i <OCR (Z wysz. tekstu)> jednocześnie. W takim wypadku na ekranie Podstawowych funkcji skanowania i wysyłania pozycja <PDF (Skompresowa.)> albo <XPS (Skompresowa.)> jest wyświetlana jako format pliku.
Jeżeli wybierzesz ustawienie <Word> dla formatu <OOXML>, można usuwać zeskanowane obrazy tła. Można generować pliki Worda, które mogą być z łatwością edytowalne bez niepotrzebnych obrazów. <Załącz obrazy tła do pliku Word>
Jeżeli w danym momencie korzystasz z funkcji <Skanuj i zapisz>, język OCR można określić tylko wtedy, gdy ustawienie <Word> zostało wybrane dla opcji <OOXML> lub skonfigurowano ustawienie <OCR (Priorytet precyzji)> dla opcji <PDF>.
|
Rezultaty działania funkcji OCR nie są zadowalające
Podczas tworzenia przeszukiwalnych plików PDF/XPS/OOXML, proces OCR (optyczne rozpoznawanie znaków) może nie być prawidłowo przeprowadzany. Przyczyną mogą być nieprawidłowe ustawienia urządzenia, języka, rodzaju znaków lub formatu dokumentu oryginalnego, które nie są odpowiednie dla przetwarzania OCR.
Sprawdzanie ustawień urządzenia i obsługiwanych języków
Możesz polepszyć działanie funkcji OCR dzięki dostosowaniu ustawień urządzenia związanych z rozpoznawaniem znaków do oryginałów albo poprzez korzystanie na oryginałach z odpowiednich typów znaków i czcionek, które mogą być rozpoznawane przez urządzenie.
Ustawienia i języki odpowiednie dla OCR
|
Element
|
Szczegóły
|
|
Ustawienia języka dla rozpoznawania znaków
|
Kiedy określony jest język z funkcją OCR wybraną w <Format Pliku>:
Znaki są rozpoznawane na podstawie języka wybranego dla każdego formatu pliku. Kiedy nie jest określony język z funkcją OCR wybraną w <Format Pliku>:
Znaki są rozpoznawane na podstawie języka wybranego w <Przełączanie Języka/Klawiatury> (<Przełączanie Języka/Klawiatury>).*1 |
|
Języki azjatyckie, które można rozpoznawać*2
|
Japoński, chiński (uproszczony), chiński (tradycyjny), koreański
Typy znaków i czcionki, które urządzenie może rozpoznawać (języki azjatyckie) |
|
Języki europejskie i grupy językowe, które można rozpoznawać
|
Języki:
angielski, francuski, włoski, niemiecki, hiszpański, holenderski, portugalski, albański, kataloński, duński, fiński, islandzki, norweski, szwedzki, chorwacki, czeski, węgierski, polski, słowacki, estoński, łotewski, litewski, rosyjski, grecki, turecki, słoweński*3, rumuński*3, bułgarski*3, hebrajski*3 Grupy językowe:
zachodnioeuropejska (ISO)*4, środkowoeuropejska (ISO)*5, bałtycka (ISO)*6 Typy znaków i czcionki, które urządzenie może rozpoznawać (języki europejskie) |
*1 Na liście mogą być wyświetlane inne języki. Jeżeli wybierzesz angielski, francuski, włoski, niemiecki, hiszpański, tajski lub wietnamski, język będzie rozpoznawany jako zachodnioeuropejski (ISO).
*2 Języki azjatyckie nie mogą zostać wykryte, kiedy wybrana jest opcja <OCR (Priorytet precyzji)>.
*3 Można wybrać, tylko gdy skonfigurowano opcję <OCR (Priorytet precyzji)>.
*4 Wliczając angielski, francuski, włoski, niemiecki, hiszpański, holenderski, portugalski, albański, kataloński, duński, fiński, islandzki, norweski i szwedzki.
*5 Wliczając chorwacki, czeski, węgierski, polski i słowacki.
*6 Wliczając estoński, łotewski i litewski.
Typy znaków i czcionki, które urządzenie może rozpoznawać (języki azjatyckie)
|
Element
|
Szczegóły
|
|
Rodzaje znaków, które można rozpoznawać
|
Japoński:
znaki alfanumeryczne, znaki Kana, znaki Kanji (pierwszy poziom JIS i niektóre z drugiego poziomu JIS), symbole Chiński (uproszczony):
znaki alfanumeryczne, chińskie znaki, symbole (GB2312-80) Chiński (tradycyjny):
znaki alfanumeryczne, chińskie znaki, symbole (Big5) Koreański:
znaki alfanumeryczne, chińskie znaki, znaki Hangul, symbole (KSC5601) |
|
Czcionki, które można rozpoznawać
|
Obsługiwanych jest wiele czcionek (Zaleca się stosowanie Ming-cho.)
Można rozpoznawać kursywy.
|
|
Czcionki wykorzystane dla znaków przekształconych (wyłącznie dla plików w formacie Word).
|
Japoński:
znaki azjatyckie: MS Mincho Znaki europejskie: Century Chiński (uproszczony):
znaki azjatyckie: SimSun Znaki europejskie: Calibri Chiński (tradycyjny):
znaki azjatyckie: PMingLiU Znaki europejskie: Calibri |
Typy znaków i czcionki, które urządzenie może rozpoznawać (języki europejskie)
|
Element
|
Szczegóły
|
|
Rodzaje znaków, które można rozpoznawać
|
Znaki alfanumeryczne, znaki specjalne dla rozpoznanego języka*1, symbole
|
|
Czcionki, które można rozpoznawać
|
Obsługiwanych jest wiele czcionek (Times, Century i Arial są zalecane).*2
Nie można rozpoznawać kursywy.
|
|
Czcionki wykorzystane dla znaków przekształconych (wyłącznie dla plików w formacie Word).
|
Calibri
Kursywa nie jest odtwarzana.
|
*1 Można rozpoznawać poniższe, znaki specjalne języka greckiego. Można również rozpoznawać znaki specjalne dla każdego języka. Niektóre znaki specjalne nie mogą być rozpoznawane, w zależności od języka.
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ, υ, φ, χ, ψ, ω
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ, υ, φ, χ, ψ, ω
*2 Gdy wybrana jest opcja <OCR (Priorytet precyzji)>, czcionki Arial, Times New Roman i Courier New są rozpoznawane.
Sprawdzanie formatu oryginalnych dokumentów
Korzystaj z oryginałów odpowiednich do przetwarzania OCR w celu polepszenia precyzji tego procesu podczas tworzenia przeszukiwalnych plików PDF/XPS/OOXML.
|
Element
|
Szczegóły
|
|
Format oryginalny
|
Drukowane dokumenty, dokumentu programu Word (dokumenty zawierające tekst, grafiki, fotografie lub tabelki - bez pochylonych znaków).
|
|
Format tekstu
|
Pismo poziome i pionowe (dokumenty zawierające tekst w poziomie i w pionie mogą być rozpoznawane).
Dla języków europejskich i koreańskiego dostępne jest wyłącznie rozpoznawanie tekstu w poziomie.
Od jednej do trzech kolumn, bez skomplikowanych ustawień kolumn.
|
|
Rozmiar znaku
|
8 do 40
|
|
Format tabeli (dla plików w formacie programu Word)
|
Tabele spełniające poniższe warunki:
Tabele składające się z kwadratów podzielonych wyraźnymi liniami
Tabele składające się z maksymalnie 32 kolumn
Tabele składające się z maksymalnie 32 rzędów
|
|
|
Niektóre oryginały odpowiednie do przetwarzania OCR mogą nie być przetwarzane prawidłowo.Wysoka precyzja może być niemożliwa do osiągnięcia w przypadku oryginałów zawierających znaczne ilości tekstu na poszczególnych stronach.
Znaki mogą być zamieniane na przypadkowe znaki lub mogą być pomijane ze względu na kolor tła oryginału, formę i rozmiar znaków lub też ich pochylenie.*
Paragrafy, podziały linii lub tabel mogą nie być odwzorowane.*
Niektóre części ilustracji, fotografii lub pieczęci mogą być rozpoznawane jak znaki i na ich miejscu urządzenie może wstawić te znaki*.
* Jeżeli jako format plików wybrano format programu Word.
|