Beolvasás OCR-funkcióval
 | Ez a mód OCR (optikai karakterfelismerés) segítségével készít adatkivonatot, amelyet szövegként fel lehet ismerni a beolvasott képen, majd kereshető PDF-/XPS-/OOXML- (pptx/docx) fájlt hoz létre. Ha fájlformátumként PDF vagy XPS opciót ad meg, akkor a <Kompakt> opciót is beállíthatja. A funkcióhoz szükséges kiegészítőkre és fájlformátumokra vonatkozó információkért lásd: Rendszer-kiegészítők. |
Beolvasás OCR-funkcióval
1
Helyezze be az eredeti dokumentumot. Az eredetik elhelyezése
2
Nyomja meg a <Beolvasás és adás> gombot. <Főmenü> képernyő
3
Adja meg a rendeltetési helyet a Beolvasás alapképernyőn. Beolvasás alapképernyő
4
Adja meg szükség szerint a beolvasási beállításokat. Az eredetik beolvasásának alapvető műveletei
5
Válassza ki a fájltípust.
Ha a több oldalt egy oldalt tartalmazó fájlokban kívánja továbbítani, nyomja meg az <Oldalakra bont>  gombot, adja meg az osztandó lapok számát nyomja meg az <OK> gombot. Ha egyetlen fájlként kívánja a képeket beolvasni, akkor nyomja meg az <Oldalakra bont> <Beállítás törlése> gombot.
gombot, adja meg az osztandó lapok számát nyomja meg az <OK> gombot. Ha egyetlen fájlként kívánja a képeket beolvasni, akkor nyomja meg az <Oldalakra bont> <Beállítás törlése> gombot.
 PDF kiválasztása
PDF kiválasztása
1 | Válassza a <PDF> beállítást 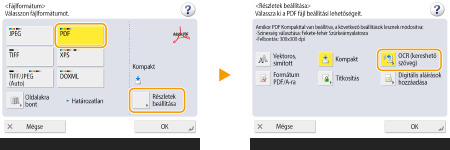 |
2 | Válassza ki az OCR-funkcióhoz használni kívánt nyelvet |
XPS kiválasztása
1 | Válassza az <XPS> beállítást 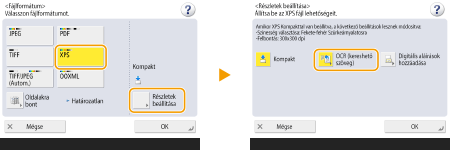 |
2 | Válasszon egy OCR-funkcióhoz használni kívánt nyelvet |
Word formátum kiválasztása OOXML esetében
1 | Válassza az <OOXML> lehetőséget 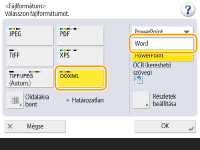  Az OCR-funkció nyelvének módosításához nyomja meg a <Részletek beállítása> Válasszon egy nyelvet vagy nyelvcsoportot a beolvasott dokumentumokban használt nyelvnek megfelelően. |
PowerPoint formátum kiválasztása OOXML esetében
1 | Válassza az <OOXML> lehetőséget  |
2 | Válasszon egy OCR-funkcióhoz használni kívánt nyelvet |
6
Nyomja meg az <OK> gombot.
|
Ha a <PDF; OCR>, <XPS; OCR> vagy <OOXML; OCR> fájlformátumot választja, és a <Gyors beolvasás> beállítása <Be> az <OCR (Text Searchable) Settings>/<OCR (Prioritize Speed)> képernyőn, akkor a készülék érzékeli az eredeti tájolását, és küldés előtt szükség esetén automatikusan elforgatja a dokumentumot. <OCR (kereshető szöveg) beállítás> Ha a <PDF> vagy <XPS> fájlformátumot választja, akkor egyszerre választhatja a <Kompakt> és <OCR (kereshető szöveg)> opciókat. Ebben az esetben a Beolvasás és Küldés alapképernyőjén a <PDF; Kompakt> vagy <XPS; Kompakt> jelenik meg fájlformátumként. Ha a <Word> opciót választja az <OOXML> lehetőségnél, akkor beállíthatja, hogy a készülék törölje a beolvasott háttérképeket. Könnyen szerkeszthető, a nem kívánt képek nélküli Word fájlokat generálhat. <Háttérképeket is a Word fájlban> |
Az OCR eredménye nem kielégítő
Kereshető szöveges PDF-/XPS-/OOXML-fájlok létrehozásakor előfordulhat, hogy az OCR (optikai karakterfelismerés) nem sikerül megfelelően. Ez azért történhet, mert a készülék vagy nyelv beállításai, az eredeti dokumentum betűtípusa vagy formátuma nem megfelelő az OCR-feldolgozáshoz.
A készülékbeállítások és a támogatott nyelvek ellenőrzése
Az OCR-feldolgozás eredményének javításához állítsa be a készülék karakterfelismerésre vonatkozó paramétereit az eredetikhez igazodva, vagy az eredetikben használjon megfelelő betűtípusokat, hogy a készülék felismerhesse azokat.
OCR-feldolgozás beállításai és nyelvei
Elem | Részletek |
A karakterfelismerés nyelvi beállításai | Ha az OCR választása esetén a <Fájlformátum> beállításánál van nyelv megadva: A karakterek felismerése a fájlformátumnál megadott nyelv alapján történik. Ha az OCR választása esetén a <Fájlformátum> beállításnál nincs nyelv megadva: A karakterek felismerése a <Nyelv/Billentyűzet váltás> (<Nyelv/Billentyűzet váltás>) beállításnál választott nyelv alapján történik.*1 |
Felismerhető ázsiai nyelvek | Japán, kínai (egyszerűsített), kínai (hagyományos), koreai Felismerhető betűtípusok (ázsiai nyelvek) |
Felismerhető európai nyelvek és nyelvcsoportok | Nyelvek: angol, francia, olasz, német, spanyol, holland, portugál, albán, katalán, dán, finn, izlandi, norvég, svéd, horvát, cseh, magyar, lengyel, szlovák, észt, lett, litván, orosz, görög, török Nyelvcsoportok: nyugat-európai (ISO)*2, közép-európai (ISO)*3, balti (ISO)*4 Felismerhető betűtípusok (európai nyelvek) |
*1 A listában látható nyelvek eltérőek lehetnek. Ha angol, francia, olasz, német, spanyol, thai vagy vietnámi nyelvet választ, akkor a funkció nyugat-európai (ISO) nyelvként azonosítja a nyelvet.
*2 Angol, francia, olasz, német, spanyol, holland, portugál, albán, katalán, dán, finn, izlandi, norvég és svéd.
*3 Horvát, cseh, magyar, lengyel és szlovák.
*4 Észt, lett és litván.
Felismerhető betűtípusok (ázsiai nyelvek)
Elem | Részletek |
Felismerhető karaktertípusok | Japán: Alfanumerikus karakterek, kana karakterek, kanji karakterek (JIS első szint, és részben a JIS második szint), szimbólumok Kínai (egyszerűsített): Alfanumerikus karakterek, kínai karakterek, szimbólumok (GB2312-80) Kínai (hagyományos): Alfanumerikus karakterek, kínai karakterek, szimbólumok (Big5) Koreai: Alfanumerikus karakterek, kínai karakterek, hangul karakterek, szimbólumok (KSC5601) |
Felismerhető betűtípusok | Többféle betűtípus támogatott. (Ming-cho típus ajánlott.) A dőlt betűs karakterek nem ismerhetők fel. |
Konvertált karakterekhez használt betűtípusok (csak ha a Word van fájlformátumként kiválasztva) | Japán: Ázsiai karakterek: MS Mincho Európai karakterek: Century Kínai (egyszerűsített): Ázsiai karakterek: SimSun Európai karakterek: Calibri Kínai (hagyományos): Ázsiai karakterek: PMingLiU Európai karakterek: Calibri |
Felismerhető betűtípusok (európai nyelvek)
Elem | Részletek |
Felismerhető karaktertípusok | Alfanumerikus karakterek, a felismert nyelv speciális karakterei*, szimbólumok |
Felismerhető betűtípusok | Többféle betűtípus támogatott. (Times, Century és Arial ajánlott.) A dőlt betűs karakterek nem ismerhetők fel. |
Konvertált karakterekhez használt betűtípusok (csak ha a Word van fájlformátumként kiválasztva) | Calibri A dőlt betűs stílust a konvertálás nem őrzi meg. |
* A következő speciális görög betűk ismerhetők fel. Az egyes nyelvek speciális karakterei szintén felismerhetők. Egy-egy nyelv egyes speciális karakterei nem ismerhetők fel.
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ,υ, φ, χ, ψ, ω
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ,υ, φ, χ, ψ, ω
Az eredeti dokumentumok formátumának ellenőrzése
Kereshető PDF-/XPS-/OOXML-fájlok létrehozásakor a feldolgozás pontosságának javítása érdekében használjon OCR-feldolgozáshoz megfelelő eredetiket.
Elem | Részletek |
Eredeti formátuma | Nyomtatott dokumentumok, szövegszerkesztő-dokumentumok (szöveget, grafikát, fényképeket vagy táblázatot tartalmazó és ferde szöveget nem tartalmazó dokumentumok) |
Szövegformátum | Vízszintes és függőleges szövegirány (a vízszintes és függőleges szöveget is tartalmazó dokumentumok is felismerhetők) Az európai nyelvek és a koreai nyelv esetében csak a vízszintes szövegirány ismerhető fel. Egy és három közötti számú oszlopot tartalmazó, összetett oszlopbeállítás nélküli dokumentumok |
Karakterek mérete | 8–40 pont |
Táblázatos formátum (csak Word formátum esetén) | A táblázatoknak teljesíteniük kell a következő feltételeket: A táblázatoknak folyamatos vonalakkal elválasztott téglalapokból kell állniuk A táblázatok legfeljebb 32 oszlopot tartalmazhatnak A táblázatok legfeljebb 32 sort tartalmazhatnak |
 |
Előfordulhat, hogy egyes OCR-feldolgozásra alkalmas eredetik feldolgozása nem lesz megfelelő.Az egyes oldalakon nagy mennyiségű szöveget tartalmazó eredetik esetében előfordulhat, hogy nagy pontosság nem érhető el. Az eredeti háttérszíne, a karakterek formája és mérete vagy ferde karakterek miatt előfordulhat, hogy a karakterek helyén nem kívánt karakterek jelennek meg vagy a karakterek hiányoznak.* Előfordulhat, hogy a bekezdések, sortörések vagy táblázatok nem lesznek reprodukálhatók.* Előfordulhat, hogy az illusztrációk, fényképek vagy bélyegzők egyes részeit a szoftver karakterként ismeri fel és karakterekkel helyettesíti.* * Ha a Word van fájlformátumként kiválasztva. |