Optično branje s funkcijo OCR
 | Ta način omogoča izvajanje OCR (optično prepoznavanje znakov) za ustvarjanje izvlečka podatkov iz optično prebrane slike, ki so lahko prepoznani kot besedilo, in ustvarjanje datoteke PDF/XPS/OOXML (pptx/docx), ki omogoča iskanje besedila. Nastavite lahko tudi <Kompakt>, če za obliko zapisa datoteke izberete PDF ali XPS. Za informacije o dodatnih izdelkih, ki so potrebni za uporabo te funkcije, in o oblikah zapisa datotek glejte Sistemske možnosti. |
Optično branje s funkcijo OCR
1
Položite izvirnik. Polaganje izvirnikov
2
Pritisnite <Skeniranje in oddaja>. Zaslon <Domov>
3
Na zaslonu z osnovnimi nastavitvami optičnega branja izberite prejemnika. Zaslon z osnovnimi nastavitvami optičnega branja
4
Po potrebi določite nastavitve skeniranja. Osnovni postopki za optično branje izvirnikov
5
Izberite format datoteke.
Če želite ločiti več slik in jih poslati kot posamezne datoteke, katerih vsaka sestoji iz samo ene strani, pritisnite <Razdeli v strani>  vnesite število strani, na katere jih želite ločiti pritisnite <OK>. Če želite optično prebrati slike v eno datoteko, pritisnite <Razdeli v strani> <Preklic nast.>.
vnesite število strani, na katere jih želite ločiti pritisnite <OK>. Če želite optično prebrati slike v eno datoteko, pritisnite <Razdeli v strani> <Preklic nast.>.
 Izbira PDF
Izbira PDF
1 | Izberite <PDF> 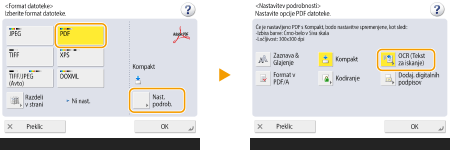 |
2 | Izberite jezik za OCR |
Izbira XPS
1 | Izberite <XPS> 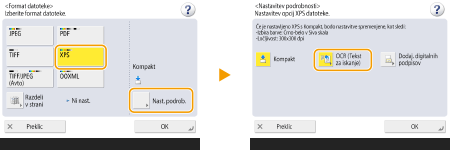 |
2 | Izberite jezik za OCR |
Izbira oblike zapisa OOXML za program Word
1 | Izberite <OOXML> 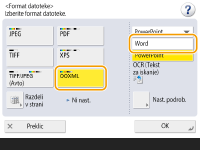  Če želite spremeniti jezik za OCR, pritisnite <Nast. podrob.> Izberite jezik ali jezikovno skupino glede na jezik, ki je uporabljen v dokumentih za optično branje. |
Izbira oblike zapisa OOXML za program PowerPoint
1 | Izberite <OOXML> 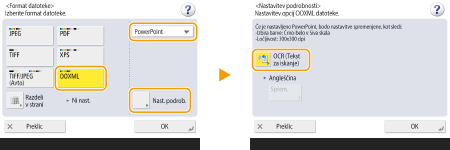 |
2 | Izberite jezik za OCR |
6
Pritisnite <OK>.
|
Če kot obliko zapisa datoteke izberete <PDF; OCR>, <XPS; OCR> ali <OOXML; OCR> in je možnost <Izpop. sken.> nastavljena na <Da> v nastavitvah <OCR (Text Searchable) Settings>/<OCR (Prioritize Speed)>, naprava zazna usmerjenost izvirnika in ga samodejno zavrti, preden dokument pošlje. <Nastavitve OCR (Tekst za iskanje)> Če kot obliko zapisa datoteke izberete <PDF> ali <XPS>, lahko hkrati nastavite <Kompakt> in <OCR (Tekst za iskanje)>. V tem primeru je kot oblika zapisa datoteke na zaslonu z osnovnimi nastavitvami optičnega branja in pošiljanja prikazana možnost <PDF; Compact> ali <XPS; Kompakt>. Če za <OOXML> izberete <Word>, lahko nastavite, da se optično prebrane slike ozadja izbrišejo. Ustvarite lahko Wordove datoteke brez neželenih slik, ki jih je enostavno urejati. <Vključitev slik v ozadju v datoteko Word> |
Rezultati OCR niso zadovoljivi
Če ustvarite datoteke PDF/XPS/OOXML, po katerih se lahko išče besedilo, se OCR (optično prepoznavanje znakov) morda ne bo pravilno izvedlo. Razlog za to je lahko, da nastavitve naprave ali jezik, vrste znakov, pisave ali oblika izvirnega dokumenta niso primerni za OCR.
Preverjanje nastavitev naprave in podprtih jezikov
OCR lahko izboljšate tako, da prilagodite nastavitve naprave za prepoznavanje znakov tako, da bodo ustrezale izvirnikom, ali z uporabo ustreznih vrst znakov ali pisav v izvirnikih, tako da lahko naprava prepozna znake.
Nastavitve in jeziki za OCR
Element | Podrobnosti |
Jezikovne nastavitve za prepoznavanje znakov | Ko je jezik določen z izbranim OCR v <Datot. format>: Znaki se prepoznavajo glede na jezik, ki ga izberete za vsako obliko zapisa datoteke. Ko jezik ni določen z izbranim OCR v <Datot. format>: Znaki se prepoznavajo glede na jezik, ki ga izberete v nastavitvi <Preklop Jezik/Tipkovnica> (<Preklop Jezik/Tipkovnica>).*1 |
Podprti azijski jeziki za prepoznavanje znakov | Japonščina, kitajščina (poenostavljena), kitajščina (tradicionalna) in korejščina Podprte vrste znakov in pisave (azijski jeziki) |
Podprti evropski jeziki in jezikovne skupine za prepoznavanje znakov | Jeziki: angleščina, francoščina, italijanščina, nemščina. španščina, nizozemščina, portugalščina, albanščina, katalonščina, danščina, finščina, islandščina, norveščina, švedščina, hrvaščina, češčina, madžarščina, poljščina, slovaščina, estonščina, letonščina, litovščina, ruščina, grščina in turščina Jezikovne skupine: zahodnoevropska (ISO)*2, srednjeevropska (ISO)*3, baltska (ISO)*4 Podprte vrste znakov in pisave (evropski jeziki) |
*1 Na seznamu prikazani jeziki se lahko razlikujejo. Če izberete angleščino, francoščino, italijanščino, nemščino, španščino, tajščino ali vietnamščino, bo jezik prepoznan kot zahodnoevropski (ISO).
*2 Vključuje angleščino, francoščino, italijanščino, nemščino, španščino, nizozemščino, portugalščino, albanščino, katalonščino, danščino, finščino, islandščino, norveščino in švedščino.
*3 Vključuje hrvaščino, češčino, madžarščino, poljščino in slovaščino.
*4 Vključuje estonščino, letonščino in litovščino.
Podprte vrste znakov in pisave (azijski jeziki)
Element | Podrobnosti |
Podprte vrste znakov za prepoznavanje znakov | Japonščina: alfanumerični zanki, znaki Kana, znaki Kanji (prva raven JIS, delno druga raven JIS), simboli Kitajščina (poenostavljena): alfanumerični znaki, kitajski znaki, simboli (GB2312-80) Kitajščina (tradicionalna): alfanumerični znaki, kitajski znaki, simboli (Big5) Korejščina: alfanumerični znaki, kitajski znaki, znaki Hangul, simboli (KSC5601) |
Podprte pisave za prepoznavanje znakov | Podprtih je več pisav. (Priporočena je pisava Ming-cho.) Ležečih znakov ni mogoče prepoznati. |
Pisave, ki se uporabljajo za pretvorjene znake (samo če je za obliko zapisa datoteke izbran Word) | Japonščina: azijski znaki: MS Mincho evropski znaki: Century Kitajščina (poenostavljena): azijski znaki: SimSun evropski znaki: Calibri Kitajščina (tradicionalna): azijski znaki: PMingLiU evropski znaki: Calibri |
Podprte vrste znakov in pisave (evropski jeziki)
Element | Podrobnosti |
Podprte vrste znakov za prepoznavanje znakov | Alfanumerični znaki, posebni znaki za prepoznani jezik*, simboli |
Podprte pisave za prepoznavanje znakov | Podprtih je več pisav. (Priporočene so pisave Times, Century in Arial.) Ležeče znake je mogoče prepoznati. |
Pisave, ki se uporabljajo za pretvorjene znake (samo če je za obliko zapisa datoteke izbran Word) | Calibri Ležečega sloga ni mogoče prepoznati. |
* Naslednje posebne grške črke je mogoče prepoznati. Prepoznani so lahko tudi posebni znaki za posamezne jezike. Določenih posebnih znakov ni mogoče prepoznati, kar je odvisno od jezika.
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ,υ, φ, χ, ψ, ω
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ,υ, φ, χ, ψ, ω
Preverjanje oblike zapisa izvirnih dokumentov
Za izboljšanje natančnosti pri ustvarjanju datotek PDF/XPS/OOXML uporabite izvirnike, primerne za OCR.
Element | Podrobnosti |
Izvirni format | Natisnjeni dokumenti, dokumenti urejevalnika besedila Word (dokumenti, sestavljeni iz besedila, grafik, fotografij ali tabel in brez nagnjenih znakov) |
Besedilna oblika | Vodoravna in navpična smer besedila (prepoznati je mogoče tudi dokumente, ki vsebujejo vodoravno in navpično smer besedila) Za evropske jezike in korejščino je mogoče prepoznati le vodoravno napisano besedilo. Dokumenti z enim do tremi stolpci besedila brez zapletenih nastavitev za stolpce |
Velikost znakov | 8 do 40 točk |
Tabelarična oblika (samo za obliko zapisa Word) | Tabele, ki ustrezajo naslednjim pogojem: Tabele, ki so sestavljene iz kvadratov, ki so razdeljeni s polnimi črtami Tabele z do 32 stolpci Tabele z do 32 vrsticami |
 |
Nekateri izvirniki, primerni za OCR, morda ne bodo pravilno prepoznani.Pri izvirnikih z veliko količino besedila na vsaki strani velika natančnost morda ne bo mogoča. Znaki se lahko zamenjajo z neustreznimi znaki ali pa so izpuščeni zaradi barve ozadja izvirnika, oblike in velikosti znakov ali nagnjenih znakov.* Odstavkov, prelomov vrstic ali tabel morda ni mogoče prepoznati.* Nekateri deli ilustracij, fotografij ali odtisi so lahko prepoznani kot znaki in so nadomeščeni z znaki.* * Če je za obliko zapisa datoteke izbran Word. |