סריקה עם פונקציית ה-OCR
 | מצב זה מאפשר לבצע OCR (זיהוי תווים אופטי) על מנת לחלץ נתונים שניתן לזהותם כטקסט מתוך התמונה הנסרקת, וליצור קובץ PDF/XPS/OOXML (pptx/docx) שניתן לחפש בו. ניתן גם להגדיר את האפשרות <דחיסה> במידה שאתה בוחר PDF או XPS בתור תבנית הקובץ. למידע על המוצרים האופציונליים הנדרשים לשימוש בפונקציה זו ועל תבניות הקובץ, ראה אפשרויות מערכת. |
סריקה עם OCR
1
הנח את מסמך המקור. הצבת מסמכי מקור
2
לחץ על <סריקה ושליחה>. המסך <בית>
3
ציין את היעד במסך תכונות הסריקה הבסיסיות. מסך תכונות הסריקה הבסיסיות
4
ציין את הגדרות הסריקה כנדרש. פעולות בסיסיות לסריקת מסמכי מקור
5
בחר תבנית קובץ.
אם ברצונך להפריד בין תמונות מרובות ולשלוח אותן כקבצים נפרדים המכילים עמוד אחד כל אחד, לחץ על <חלוקה לדפים>  הזן את מספר העמודים שאותם יש לחלק באמצעות לחץ על <אישור>. אם ברצונך לסרוק את התמונות כקובץ אחד, לחץ על <חלוקה לדפים> <הגדרות ביטול>.
הזן את מספר העמודים שאותם יש לחלק באמצעות לחץ על <אישור>. אם ברצונך לסרוק את התמונות כקובץ אחד, לחץ על <חלוקה לדפים> <הגדרות ביטול>.
 לבחירת PDF
לבחירת PDF
1 | בחר <PDF> 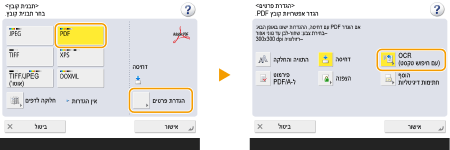 |
2 | בחר את השפה לשימוש ב-OCR |
לבחירת XPS
1 | בחר <XPS> 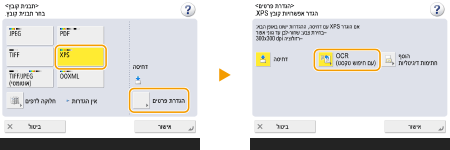 |
2 | בחר שפה לשימוש ב-OCR |
לבחירת תבנית Word עבור OOXML
1 | בחר <OOXML> 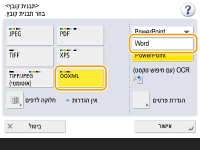  לשינוי השפה לשימוש ב-OCR, לחץ על <הגדרת פרטים> בחר שפה או קבוצת שפות בהתאם לשפת המסמכים שנסרקו. |
לבחירת תבנית PowerPoint עבור OOXML
1 | בחר <OOXML> 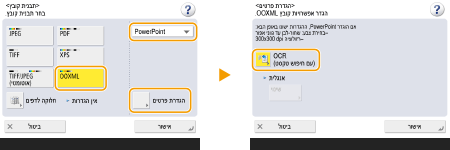 |
2 | בחר שפה לשימוש ב-OCR |
6
לחץ על <אישור>.
|
אם תבחר <PDF; OCR>, <XPS; OCR>, או <OOXML; OCR> כתבנית הקובץ, והאפשרות <סריקה חכמה> תוגדר כ-<מופעל> ב-<OCR (Text Searchable) Settings>/<OCR (תעדף מהירות)>, כיוון מסמך המקור יזוהה, והמסמך יסובב באופן אוטומטי לפני שליחתו, לפי הצורך. <OCR (עם חיפוש טקסט) הגדרות> אם תבחר <PDF> או <XPS> כתבנית הקובץ, תוכל להגדיר <דחיסה> ו-<OCR (עם חיפוש טקסט)> באותו הזמן. במקרה זה, <PDF; דחיסה> או <XPS; דחיסה> יוצג כתבנית הקובץ במסך תכונות הסריקה והשליחה הבסיסיות. אם תבחר <Word> עבור <OOXML>, תוכל להגדיר כי תמונות הרקע שנסרקו יימחקו. ניתן להפיק קבצי Word שקל לערוך אותם, ללא תמונות בלתי רצויות. <כלול תמונות רקע בקובץ Word> |
תוצאות ה-OCR אינן משביעות רצון
כשאתה יוצר קבצי PDF/XPS/OOXML שניתן לחפש בהם טקסט, ייתכן שעיבוד ה-OCR (זיהוי תווים אופטי) לא יתבצע היטב. הדבר עלול לקרות במקרה שהגדרות המכשיר, או השפה, סוג התווים או התבנית של מסמך המקור, אינם מתאימים לעיבוד OCR.
בדיקת הגדרות המכשיר ושפות נתמכות
ניתן לשפר את עיבוד ה-OCR באמצעות התאמה אישית של הגדרות המכשיר הנוגעות לזיהוי תווים בהתאם למסמכי המקור, או באמצעות שימוש בסוגי תווים או גופנים במסמכי המקור באופן שיאפשר למכשיר לזהות את התווים.
הגדרות ושפות לעיבוד OCR
פריט | פרטים |
הגדרות שפה לצורך זיהוי תווים | כשמציינים את השפה והאפשרות OCR מסומנת ב-<תבנית קובץ>: התווים יזוהו בהתאם לשפה שתבחר עבור כל תבנית הקובץ. שלא מציינים את השפה והאפשרות OCR מסומנת ב-<תבנית קובץ>: התווים יזוהו בהתאם לשפה שתבחר ב-<בחירת שפה/מקלדת> (<בחירת שפה/מקלדת>).*1 |
שפות אסייתיות ניתנות לזיהוי | יפנית, סינית (פשוטה), סינית (מסורתית), קוריאנית סוגי תווים וגופנים ניתנים לזיהוי (שפות אסייתיות) |
שפות וקבוצות שפות אירופיות ניתנות לזיהוי | שפות: אנגלית, צרפתית, איטלקית, גרמנית, ספרדית, הולנדית, פורטוגזית, אלבנית, קטלאנית, דנית, פינית, איסלנדית, נורווגית, שוודית, קרואטית, צ'כית, הונגרית, פולנית, סלובקית, אסטונית, לטבית, ליטאית, רוסית, יוונית, טורקית קבוצות שפות: מערב אירופיות (ISO)*2, מרכז אירופיות (ISO)*3, בלטיות (ISO)*4 סוגי תווים וגופנים ניתנים לזיהוי (שפות אירופיות) |
*1 השפות המוצגות ברשימה עשויות להשתנות. אם תבחר אנגלית, צרפתית, איטלקית, גרמנית, ספרדית, תאילנדית או וייטנאמית, השפה שנבחר תזוהה כשפה מערב אירופית (ISO).
*2 כולל אנגלית, צרפתית, איטלקית, גרמנית, ספרדית, הולנדית, פורטוגזית, אלבנית, קטלאנית, דנית, פינית, איסלנדית, נורווגית ושוודית
*3 כולל קרואטית, צ'כית, הונגרית, פולנית וסלובקית
*4 כולל אסטונית, לטבית וליטאית
סוגי תווים וגופנים ניתנים לזיהוי (שפות אסייתיות)
פריט | פרטים |
סוגי תווים ניתנים לזיהוי | יפנית: תווים אלפא נומריים, תווי Kana ,תווי Kanji (JIS רמה ראשונה, וחלק מה-JIS רמה שניה), סמלים סינית (פשוטה): תווים אלפא נומריים, תווים סיניים, סמלים (GB2312-80) סינית (מסורתית): תווים אלפא נומריים, תווים סיניים, סמלים (Big5) קוריאנית: תווים אלפא נומריים, תווים סיניים, תווי Hangul, סמלים (KSC5601) |
גופנים ניתנים לזיהוי | גופנים רבים נתמכים. ( מומלץ הסוג Ming-cho.) תווים נטויים (Italics) אינם ניתנים לזיהוי. |
הגופנים שבהם נעשה שימוש עבור התווים שהומרו (רק כאשר בוחרים ב-Word כתבנית הקובץ) | יפנית: תווים אסייתיים: MS Mincho תווים אירופיים: Century סינית (פשוטה): תווים אסייתיים: SimSun תווים אירופיים: Calibri סינית (מסורתית): תווים אסייתיים: PMingLiU תווים אירופיים: Calibri |
סוגי תווים וגופנים ניתנים לזיהוי (שפות אירופיות)
פריט | פרטים |
סוגי תווים ניתנים לזיהוי | תווים אלפא נומריים, תווים מיוחדים של השפה המזוהה*, סמלים |
גופנים ניתנים לזיהוי | גופנים רבים נתמכים. (מומלצים Times, Century, ו-Arial.) תווים נטויים (Italics) ניתנים לזיהוי. |
הגופנים שבהם נעשה שימוש עבור התווים שהומרו (רק כאשר בוחרים ב-Word כתבנית הקובץ) | Calibri סגנון נטוי (Italics) אינו מופק בקובץ המומר. |
* התווים היווניים המיוחדים הבאים ניתנים לזיהוי. תווים מיוחדים של כל אחת מהשפות ניתנים גם כן לזיהוי. תווים מיוחדים מסוימים אינם ניתנים לזיהוי כתלות בשפות.
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ,υ, φ, χ, ψ, ω
Α, Β, Γ, Δ, Ε, Ζ, Η, Θ, Ι, Κ, Λ, Μ, Ν, Ξ, Ο, Π, Ρ, Σ, Τ, Υ, Φ, Χ, Ψ, Ω, α, β, γ, δ, ε, ζ, η, θ, ι, κ, λ, μ, ν, ξ, ο, π, ρ, σ, τ,υ, φ, χ, ψ, ω
בדיקת התבנית של מסמכי המקור
השתמש במסמכי מקור המתאימים לעיבוד OCR על מנת לשפר את הדיוק של העיבוד בעת יצירת קבצי PDF/XPS/OOXML שניתן לחפש בהם.
פריט | פרטים |
תבנית מסמך המקור | מסמכים מודפסים, מסמכים של מעבד תמלילים (מסמכים המורכבים מטקסט, גרפיקה, תצלומים או טבלאות, וללא תווים נטויים) |
תבנית הטקסט | כתב אופקי ואנכי (מסמכים הכוללים גם כתב אופקי וגם כתב אנכי ניתנים אף הם לזיהוי) בשפות אירופיות ובטקסט הכתוב בקוריאנית, ניתן לזהות רק כתב אופקי. מסמכים הכוללים עמודה עד שלוש עמודות ללא הגדרות עמודה מורכבות |
גודל תו | 8 עד 40 נקודות |
תבנית טבלה (עבור תבנית Word בלבד) | טבלאות העומדות בתנאים הבאים: טבלאות המורכבות מריבועים המופרדים בקווים רציפים טבלאות עם 32 עמודות לכל היותר טבלאות עם 32 טורים לכל היותר |
 |
ייתכן שמסמכי מקור מסוימים, המתאימים לעיבוד OCR, לא יעובדו כהלכה.ייתכן שלא ניתן יהיה לקבל רמת דיוק גבוהה בעבודה עם מסמכי מקור הכוללים כמות גדולה של טקסט בכל דף. תווים מסוימים עשויים להיות מוחלפים בתווים שגויים או להיות חסרים כתוצאה מצבע הרקע של מסמך המקור, מהצורה והגודל של התווים, או מתווים נטויים.* פסקאות, מעברי שורה וטבלאות עלולים לא להיות מופקים.* ייתכן שחלקים מסוימים של איורים, תצלומים, או הטבעות חותם יזוהו כתווים ויוחלפו בתווים.* * כאשר בוחרים ב-Word כתבנית הקובץ. |